
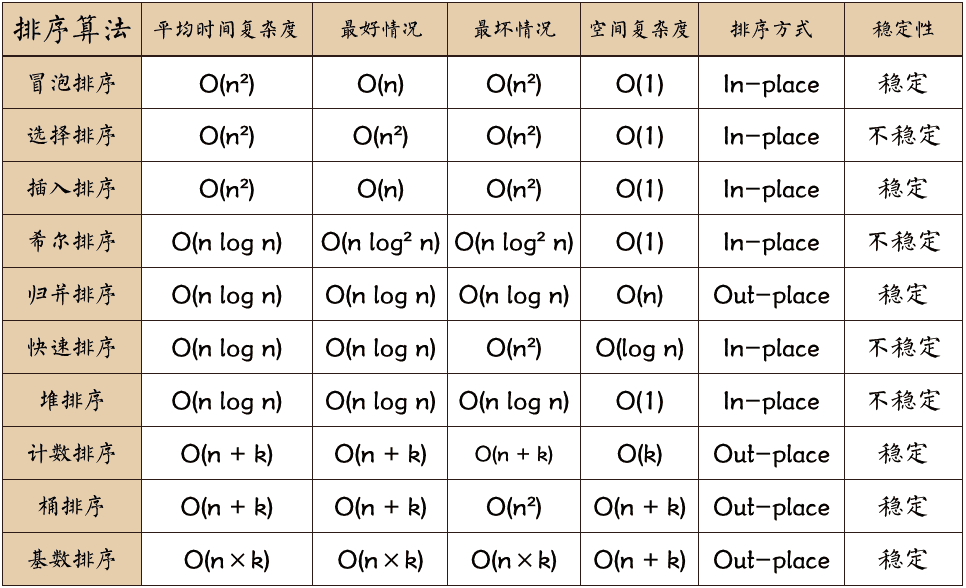
冒泡排序
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢”浮”到数列的顶端。
冒泡排序还有一种优化算法,就是立一个 flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来说并没有什么太大作用。
每次比较相邻的两个元素,如果前面的元素大于后面的元素,则将它们交换位置
时间复杂度:O(N²) (两个嵌套循环)
空间复杂度:O(1)
算法步骤
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
动图演示
什么时候最快
当输入的数据已经是正序时(都已经是正序了,我还要你冒泡排序有何用啊)。
什么时候最慢
当输入的数据是反序时(写一个 for 循环反序输出数据不就行了,干嘛要用你冒泡排序呢,我是闲的吗)。
优化
可以使用一个标志来表示是否有元素交换过位置。如果没有元素交换过位置,则说明数组已经排序好了,可以提前退出循环
提前结束有序
由于冒泡排序是相邻两元素依次相比,则若出现一轮未发生元素更换的情况下:即为数组已经有序,则可提前结束。这样的好处是当数组在前几轮对比已经有序之后可以节省不必要的元素对比次数,比如需要排序的数组为[3,1,2,4,5]这样第一大轮比较之后数组已经有序,则会再比一轮发现元素没有发生过交换即退出排序结束。
1 | // 由于冒泡是相邻两元素依次相比,则若出现一轮未发生元素更换的情况下:即为数组已经有序,则可提前结束 |
跳过部分有序
结合优化一中讨论的,我们要使得整轮都有序的情况下才可以提前结束排序操作。但当我们遇到比如 [3,2,1,4,5,6] 这种数组时,后面的4,5,6已经有序的情况下我们在每大轮的比较里可以跳过这部分的小轮两两相比,这样又可以提高一部分的效率。
1 | // 记录最后一个更换元素时的索引值,下一轮的比较可以自动跳过之后的有序队列 |
两极有序缩略
以上的优化总的来说都是分大小两轮,每一大轮排出一个最值到边界。而接下来我们有一个想法,就是一大轮我们同时在左右两边各排出一个最大值与最小值,这样我们的排序效率又会更进一步了。
1 | const bubbleSortOp4 = (arr) => { |
代码
1 | //测量时间 |
选择排序
每一次把数组中一个数与有序数组进行从后往前一一比较,遇到比有序数组中元素小然后插入
时间复杂度:O(N²)
空间复杂度:O(1)
算法步骤
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
动图演示
代码
1 | class SelectionSort { |
插入排序
每一次把数组中一个数与有序数组进行从后往前一一比较,遇到比有序数组中元素小然后插入。
插入排序和冒泡排序一样,也有一种优化算法,叫做拆半插入。
时间复杂度:O(N²)
空间复杂度:O(1)
算法步骤
- 将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
- 从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
动图演示
 \
\
代码
1 | private fun insertSort(array: IntArray) { |
希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录”基本有序”时,再对全体记录进行依次直接插入排序。
算法步骤
- 选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
- 按增量序列个数 k,对序列进行 k 趟排序;
- 每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
动图演示

代码
1 | private fun shellSort(array: IntArray) { |
快速排序
用到了分治的思想,以一个数为基准,把数组分为一边大、一边小,然后再分别对左、右两个数组进行相同操作,直到子数组为1。
平均时间复杂度:O(nlogn)
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
快速排序的时间复杂度分析主要包括以下两部分:
划分操作的时间复杂度:
每次划分需要遍历整个数组,从左到右扫描一遍,所以划分操作的时间复杂度是 𝑂(𝑛)
其中 n 是当前数组的长度。
递归深度的时间复杂度:
最佳情况下,每次划分后,基准将数组分成大小大致相等的两部分。这时,递归深度为 logn。
平均情况下的时间复杂度
T(n)=O(n)×O(logn)=O(nlogn)
最佳和最差情况的时间复杂度
最佳情况:
当每次划分都能将数组几乎平分时,递归深度为 logn,总时间复杂度为 O(nlogn)。
最差情况:
当每次划分都选择到数组中的最小或最大元素作为基准时,划分极不均衡,一个子数组为空,另一个子数组包含剩余的n−1 个元素。
这种情况下,递归深度为 O(n),总时间复杂度为 O(n2)。
算法步骤
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
动图演示
代码
1 | private fun quickSort(array: IntArray) { |