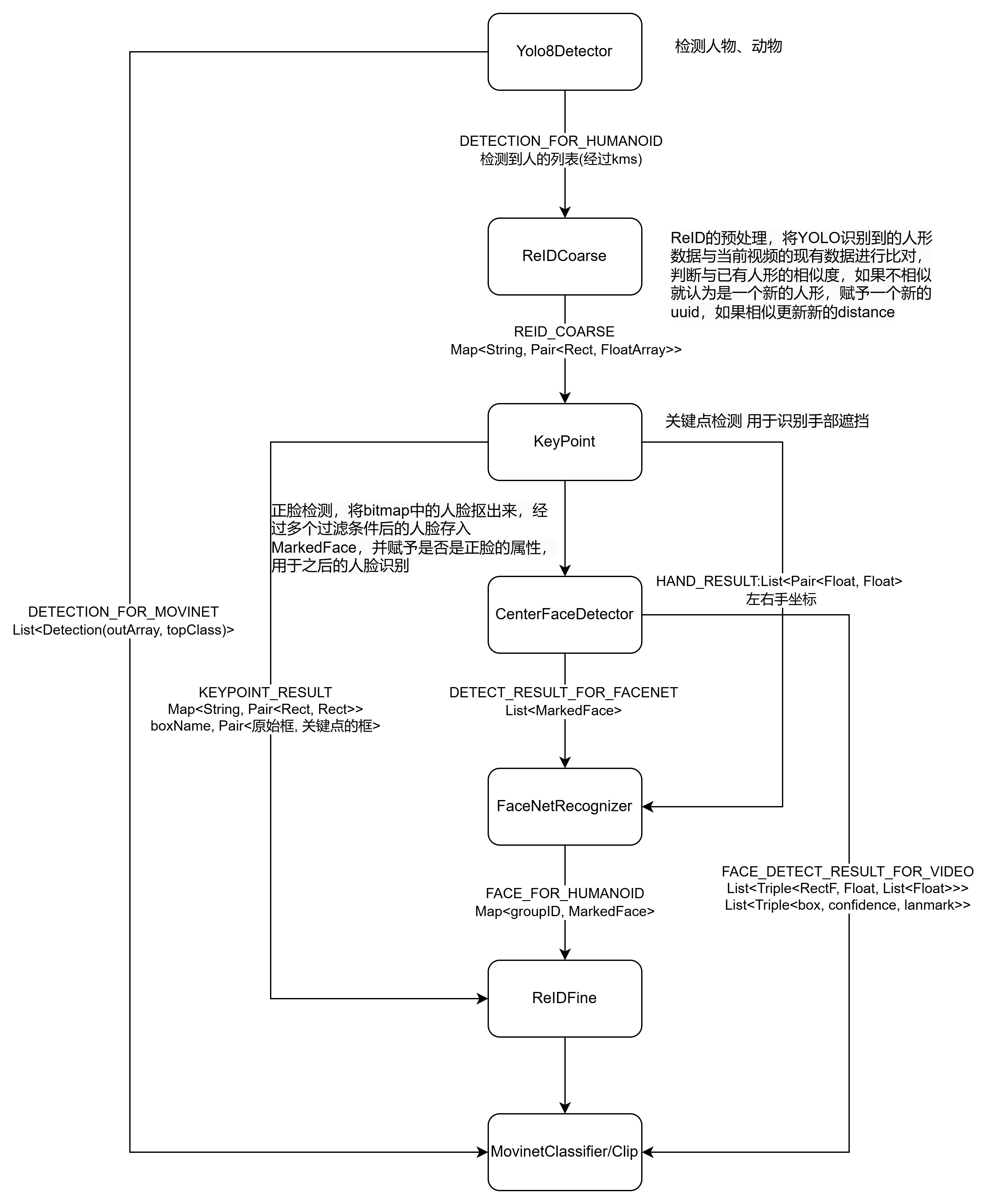
建立了一个算法管线,每一个需要计算的视频最终都会进入这里,每一帧的 bitmap 以串行的形式经过每一个 OP,得到每个 OP 的结果,包括人的识别,人脸识别,人形识别,视频理解,最终上报事件,形成标签展示在首页
整体流程
YOLO
是所有计算管线的开始,用于图像识别,在这里会上报三种事件
- 人物:连续 5 帧检测到人并且 prob>0.8,两段视频间隔 5s 以上或者一段视频长度超过 1min
- 宠物:连续 5 帧检测到人并且 prob>0.5,两段视频间隔 5s 以上或者一段视频长度超过 1min
- 与宠物玩耍: (宠物连续帧>80 || 连续 60 帧以上人与宠物的 iou 重叠>0.45) && 速度>0.2,只上报一次
ReIDCourse
这个 OP 用于将 YOLO 识别到的人形数据与当前 clip 中的现有人形数据进行比对,判断与已有人形的相似度,如果不相似就认为是一个新的人形,赋予一个新的 uuid,如果相似更新新的 distance
步骤
- 从 YOLO 中检测出的 prob>0.7 的结果
otherPersonList - 要求任意两个元素的 iou 重叠都<=0.15,如果不满足直接返回。这里的元素指的是一帧中的人形,如果 iou 过大代表两个人有重叠,会导致之后的判断存在误差
- 图像处理
- 将 YOLO 检测框的坐标映射回原始图像上,并返回一个表示在原始图像中的目标框的 Rect 对象
- 抠出人形,输入一张 bitmap,和一个 bounding box 输出根据该 bounding box 抠出来的小图
- 灰度图过滤:满足 80%以上的像素值是灰度(r=g=b)
- 推理
- 如果当前 clip 还没有人形,为当前人形创建新的 uuid,直接返回 uuid
- else 计算新人形 feature 与已有人形的欧氏距离,更新距离,返回最相似的人形 ID
- 注意这里的 ID 是 box 追踪 ID,并不是最终的人形 ID
- 输出
1 | coarseHumanoidMap[bodyBoxID] = Pair(transferBox, feature) |
KeyPoint
关键点检测 用于识别手部遮挡
拿到上一步的 ReIDCorse 的结果,Map<人形IDString, Pair<人形坐标Rect, 人形特征FloatArray>>,首先根据区域裁剪出图像,然后利用 inference 方法进行推理得到原始数组 rawArray。根据原始数组,提取手部关键点信息,筛选有效的手部关键点并计算位置。进行后处理,计算关键点的位置并更新区域大小。最终将提取的手部关键点和关键点结果存储在 item.labels 中。
输出
1 | [HAND_RESULT] -> [ReIDFine] List<Pair<Float, Float>> 手的左上角的坐标点 |
CenterFaceDetector
这个 OP 主要适用于正脸检测,将 bitmap 中的人脸抠出来,经过多个过滤条件后的人脸存入 MarkedFace,并赋予是否是正脸的属性,用于之后的人脸识别
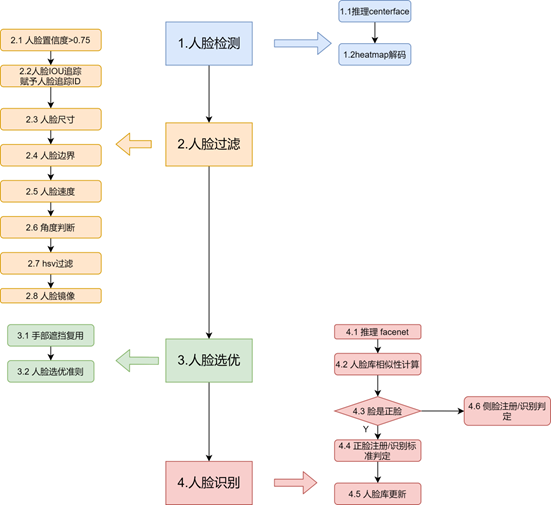
步骤
人脸检测
推理 centerface
模型输入分辨率:480x320
预处理:转化为 BCHW 形式, 在内存中的为 rrrrggggbbbb
数据格式:float32
Bitmap 解码
使用置信度阈值 0.60, NMS 阈值 0.30 解码
人脸过滤
人脸过滤目的是严格人脸识别的准入,通过所有过滤条件才允许进行人脸选优最后送去人脸识别。
人脸置信度
使用 0.75 过滤置信度低于该值的人脸
人脸 iou 追踪
通过置信度过滤的人脸进行追踪,使用 IOU(交并比)实现。当前人脸与上一帧的人脸(置信度大于 0.75)计算 IOU,并取与之 IOU 最大的人脸追踪 ID 作为当前人脸的追踪 ID,ID 相同的人脸为一个追踪序列。若该序列 ID 连续 20 帧没有检测到人脸,则该 ID 不在作为追踪参考,需要人为中断。
人脸尺寸
人脸尺寸过滤过小的人脸。最小尺寸为当前分辨率的高*0.077,若人脸 boundingbox 的高度小于最小尺寸,则放弃。
根据原始图片的分辨率有一个最小需要满足的 size(margin),要求图片的高要大于这个 margin
人脸边界
上下边界为 0.50最小尺寸,左右边界为 2最小尺寸,要求人脸 boundingbox 不能与边界区域有重叠。
由于摄像机是广角的,在四周的图像会被拉伸,根据原始图片的分辨率有一个最小需要满足的 margin,要求图片的四周往内缩 margin 的距离后,脸也需要在这个框内
人脸速度
人脸最大速度实时更新,与人脸尺寸有关,人脸 ratio(ratio = 人脸 boundingbox / 图像高)作为 x,人脸最大速度为 y,计算公式为分段函数:
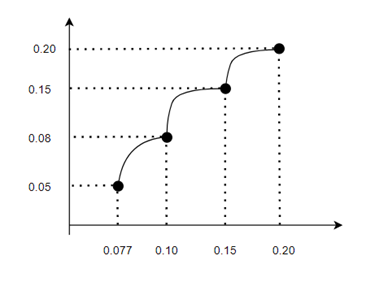
- Y = 121.37x2 + 22.78x - 0.985 (0.077<x<=0.10)
- Y = -40x2 + 11.40x - 0.66 (0.10<x<=0.0.15)
- Y = -24x2 + 9.4x - 0.72 (0.15<x<=0.20)
- Y = 0.20 (x>0.20)
人脸速度计算方式:在 2.2 进行人脸 iou 追踪时,获得该帧人脸相对于上一帧的中心点位移,用该位移作为该时刻人脸的瞬时速度。
角度判断
推理 headpose 模型,根据人脸框抠图,resize 到 224,224 的尺寸,转化为 float32 数据类型输入到模型中,返回一个数组[yall,roll,pitch]。
正脸:|pitch| < 20 && |yaw|<15
侧脸:|pitch| < 60 && |yaw|<55
角度再大就放弃,同时根据 yaw 判断是右脸还是左脸
Float,表示左眼和右眼之间的倾斜角度。该角度值表示了人脸在水平方向上的倾斜程度,以度数表示。角度值越大,表示人脸倾斜的程度越大。
Boolean,表示鼻子是否位于左眼、右眼、左嘴角和右嘴角之间。如果该值为 true,则表示鼻子位于关键点之间;如果该值为 false,则表示鼻子不在眼睛之间。
hsv 过滤
判断人脸图像三个通道 rgb 值,将 rgb 转化为 hsv 值后根据条件判断,若像素未通过 hsv 判断的数量达到人脸像素值的 1/3,则放弃。
人脸镜像
根据角度判断的结果,若是左脸(正脸侧脸都有左脸),则进行镜面反转。同时根据人脸 landmark 的左右眼角度对人脸进行矫正。
人脸选优
手部遮挡信息复用
在一个人脸追踪序列中,若当前人脸没有遮挡信息,则使用前一帧的遮挡结果。
同时,如果该序列首张或前 5 帧人脸没有遮挡信息,若当前人脸有遮挡信息,则把当前的遮挡信息复用给前几帧,这是为了避免首帧被遮挡但是无遮挡信息的人脸注册。
判断人脸是否被遮挡:
在目标检测阶段,获得人形图片后进行关键点检测,若手部关键点距离人脸框四个点的最短距离,小于人脸框对角线的 0.75,则认为该人脸被遮挡。
人脸选优准则
人脸选优是基于同一人脸追踪序列中进行选择。
当前人脸面积大于当前最佳人脸,1 分
当前人脸速度小于当前最佳人脸,3 分
当前人脸无遮挡,最佳人脸被遮挡,4 分
当前人脸角度(y,p)绝对值小于最佳人脸,2 分。
如果总得分大于等于 3 分,则更新最佳人脸为当前人脸。
虽然最佳人脸替换,但是需要暂存在追踪过程中通过人脸过滤的所有人脸进行人脸识别。
输出
1 | List<MarkedFace> |
FaceNetRecognizer
概要
这里是最终的人脸识别,本地存储人脸库的脸分为 frontFace 和 otherFace,分别是正脸和其他角度的脸(侧脸),要求手和脸之间的距离不能太近,并且加入分数计算,选择最优的一张人脸进入识别,同时在这里约束窗口,三帧连续识别到才算真的识别到一个人脸,过滤掉误识别的情况。
在识别过程中首先加载人脸库,由于图片数据很大,为了避免人脸库数量多的时候内存溢出,这里只返回 FaceUserID,实际需要图片时要再获取,将最佳的人脸列表与人脸库中其他人脸对比,如果当前脸是正脸就和 frontFaceRepository(正脸库)比对,否则和 otherFaceRepository(侧脸库)比对,从人脸库中获取对应 faceID 的 feature,与当前 face 的 feature 比较,返回最相似的距离和 ID。返回三个值(是否是已知人脸、是否是新的脸,通过 ID 拿到的脸)
以上是准备工作,拿到三个值后进入真正的识别过程
如果是已知人脸并且可以拿到人脸数据:是否替换人脸
- 如果当前 face 与 mostPossibleFaceUserForReport(人脸库中与当前 face 最相似的一个人脸)相比 speed,anglex,angley,anglez 均需要更小,代表此人脸质量更佳,返回 true
- 识别到了相互匹配的脸: 正对正,侧对侧,判断新识别到的是否比人脸库中的脸质量更高,如果更高则替换掉人脸库中的人脸,判断是否需要替换原来的人脸库中的人脸,这里包括侧脸和正脸,侧脸和侧脸比较,正脸和正脸比较
如果是新的脸并且是正脸: 注册人脸
- 当前脸与库中的所有人脸的距离均大于阈值
如果是新的脸并且是侧脸:匹配人脸
- 拿到正脸库中的每一个人脸,与其他比对一样返回最相似的人脸 ID 和 distance,如果 distance 小于给定的阈值那么认为这个侧脸有可能是该正脸的侧脸,再过滤亮度和手部遮挡及关键点,如果都满足,代表和正脸匹配上了,就将侧脸注册到侧脸库里(intelligenceRepository.insertNewFaceUser), 插入侧脸,带上该侧脸对应的可能的正脸;否则这个脸就无效
- 如果这个脸是新的脸且是侧脸,和侧脸没有匹配到,需要与正脸库的再匹配一次,因为有可能是某个正脸的侧脸
步骤
推理 facenet
Resize 到 160, 160
像素值 / 127.5 - 1.0
得到 512 维的数组作为该人脸的特征向量
人脸库相似性计算
根据当前脸的角度类型选择对应的人脸库计算余弦距离。正脸只和正脸计算,侧脸优先和侧脸匹配(阈值 0.20),若没有与之相似的侧脸再和正脸匹配(阈值 0.20)。
正脸注册/识别标准判定
该脸是正脸,并且在人脸库相似性计算时的最小余弦距离大于 0.45,则说明该人脸可以去注册一张新正脸。注册正脸还需判断:该脸是否被遮挡,该帧是否有检测到人(阈值 0.70),
若其没有被遮挡,且该帧有检测到人,则允许该张正脸注册,否则放弃。
若最小余弦距离小于 0.20 则说明改正脸识别成功,赋予相同 ID。
人脸库更新
在正脸识别的基础上,若余弦距离小于 0.10,且该人脸比人脸库中的人脸更好,则替换。判断更好的条件:速度更好,角度更小。
侧脸注册/识别判定
若该张人脸是侧脸,其与正脸匹配成功,将其当作新侧脸插入到正脸 group 中。若其与侧脸匹配成功,则插入到相同 group 中。
ReIDFine
概要
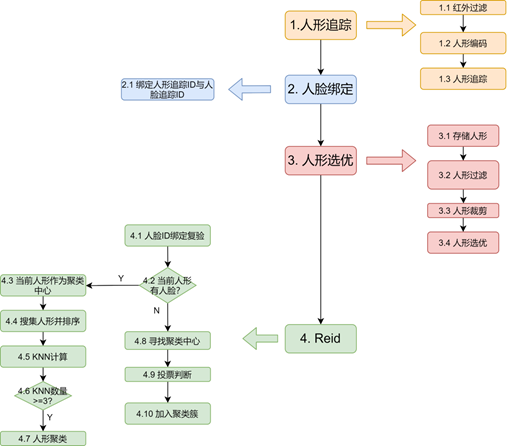
步骤
人形追踪
红外过滤
判断当前设备是否开启了红外模式,计算人形区域图像的像素 RGB 三个通道两两差值是否在 5 以内。若上述像素个数大于总像素数的 0.60,则放弃该人形。
人形编码
Resize 到 128x256
预处理:标准化
人形追踪
当前人形与上一帧人形计算距离,若距离小于阈值则判断为一个追踪序列,赋予相同的追踪 ID,否则创建新 ID。
人脸绑定
绑定人形追踪 ID 与人脸追踪 ID
获取当前的人脸检测结果,若该人形人脸关键点(关键点检测时暂存)完整,且人形框包含人脸框,则将人脸追踪 ID 与人形追踪 ID 绑定。(此处的人脸置信度大于 0.75,并暂存此时的人形)
同时将置信度大于(0.70)人脸检测结果的角度赋予该人形,作为人形的角度。
人形选优
存储人形
暂存执行上一步的人形图片用于后期复验
人形过滤
人形框的宽高比大于 0.50,躯干关键点(索引为[0 1 2 3 4 5 6 11 12 13 14])阈值>0.30 则放弃,不进行人形选优。
人形裁剪
根据关键点(索引[9,10])信息,裁剪出更紧凑的人形
人形选优
人形选优准则:优先角度最佳,若没有角度信息(2.1 没有人脸角度赋予该人形)则优先高宽比大的人形。
Reid
人脸 ID 绑定复验
使用 2.1 暂存的人形与 3.4 选优后的人形(具有相同人形追踪 ID)计算余弦距离,若距离小于 0.55 则可以进行人脸 ID 绑定。获得人脸识别结果,若人脸识别结果与人形有相同的人脸追踪 ID,则绑定人形追踪序列 ID 与人脸识别 ID。
判断人形是否有人脸 ID
判断该最佳人形是否具有人脸识别 ID,若该最佳人形具有人脸识别 ID,则其可以作为聚类中心,否则只能加入到别的中心的聚类簇中。
人形作为聚类中心
搜集人形并排序
将当前人形的特征向量与人形库中的非中心人形计算余弦距离,收集距离小于 0.50 的人形,并将其按照距离从小到大排序,获得投票序列。
KNN 计算
判断投票序列中是否存在 3NN 关系,即聚类中心人形与非中心人形的距离两两之间小于 0.50,
KNN 数量判断
若前 3 个人形(包含聚类中心)满足 3NN,则将其中的两个非中心人形加入聚类中。
人形聚类
持续判断投票序列,在序列个数小于等于 5,都需要满足 KNN 关系,大于 5,则按照投票处理。投票规则:该非中心人形与序列中的前序人形距离小于 0.50 的个数大于投票总数的一半。
举例说明:
当前序列有 A B C D E,其中 A 是聚类中心,BCDE 是通过 KNN 加入簇中。此时 E 之后还有人形 F,则 F 需要计算与 ABCDE 的余弦距离,若距离小于 0.50 的分别是 ABC,有 3 个,已经大于投票数 5 的一半,则也将 F 加入 A 的簇中
- 首先这里计算距离的时候是用的缓存,缓存中存储的是每个 bodyBoxID 下的聚类列表
- 在计算时我们首先需要考虑该人形应该属于哪一个聚类,先找到距离最小的那个聚类中心,
- 如果此时距离大于最小接受距离,直接 return
- 其次,找到聚类中心后与该聚类列表中的每一个人形计算距离,当列表没满的时候需要每一个距离都小于最小接受范围,
- 当列表满了的话,首先判断是否要插入该列表,做法就是记录每个人形与聚类中心的距离,如果当前人形的距离不是最大的,
- 那么把聚类列表中的那个距离最大的人形删除
- 最终计算得到的距离和最有可能的人形,都只可能是某一个聚类列表的中心,即聚类列表的首个元素
寻找聚类中心
若该人形没有人脸识别 ID,则其只能加入其他的聚类簇中。
投票判断
计算该人形与所有聚类中心(已经形成聚类,而不是只有聚类中心)的最短距离的中心,使用与[人形聚类] 相同规则进行判定,满足条件则加入聚类。否则暂存。
加入聚类簇
MovinetClassifier
用于视频理解
步骤
拿到经过 centerFace 的 inference 得到的结果(进入 centerFace 的每一个 bitmap 通过模型 inference 得到的 list,每个元素包括人脸的 rect,置信度,五官相关的 landmark)
拿到经过 Yolo 检测到的结果(检测到人并且置信度大于 0.65)
遍历 facelist 和 detectionList,每个元素进行比对,
- 如果人脸和人物的 iou 有两个以上存在重合,shouldReportCarryBaby = true
- 如果 detection 的高宽比<3, shouldReportCrawlingBaby = true
选帧进入模型计算,将帧收集为 48 帧,每三个分为一组,取每一组的第一个送入模型。要求帧与帧之间的距离小于 30 帧
- 按照 validFrameIndex%3 分别插入
1
2
3
4
5
6
7
8val targetLinkedList =
when ((validFrameIndex) % 3) {
0 -> linkedFrameList0
1 -> linkedFrameList1
else -> linkedFrameList2
}
targetLinkedList.add(bitmap)
总结
人形追踪
使用轻量化的网络模型获得当前帧的人性特征,并与上一帧的人形特征比较相似性,足够相似时认为同属一人并使用当前人性特征进行更新。在追踪过程中,若该人物在通过人脸识别后有对应的人脸 id,则记录该人脸 id 与前述追踪人物的对应关系。在追踪完成后,获得该人物的最佳人形特征(找到长宽比最小的人形,通常意味着最正)。
人形识别
得到一个人形序列中最优的人形之后,尝试与已经注册的人形库中的人形去匹配,如果能够匹配上则加入对应的人形队列。
如果与人形库中的任意一个人形队列都无法匹配,则尝试与同样没能匹配上的人形 buffer 中的离散人形尝试进行聚类,倘若能够聚类成功(任意人形都能够满足两两匹配),此时人形 buffer 中的这几个人形将进入人形库中形成一个新的聚类,此时聚类的中心由算法选择最具代表性的。
如果与人形 buffer 也没有能够形成聚类中心,那么将该人形加入 buffer 中,等待后续人形。
人形与人脸的关系对应
如果人形聚类中的任意一个人形与人脸绑定在一起了,此时该人形聚类中的每一个人形都会绑定上该人脸,搜索人脸可以搜素到这些人形视频。
优化
yolo 隔帧检测
隔帧检测的目的是加快检测的速度,目前的帧率是 1s20 帧,隔帧在时间缩短一半的情况下对于检测精度的下降在可接受范围内
造成的问题: 误检,扣减,比如会将沙发检测成人
解决办法: 时域滤波,多次验证,连续上报
视频理解误判
α 滤波
movinet 选取 48 帧,最终是测试了 16,31,28,80 帧,考虑到速度和准确度的两重影响因素,最终选择为 48, 每 16 帧做一次一共做三次,还需要扣背景,和场景有关需要外扩场景,由于镜头会抖动,有一帧错误就会造成识别的不准确性,所以采取信一点的策略,人不一定要在中间,但是会把你框在里面,下一帧 yolo 就会跟上再次计算
人脸选优
添加分数判断:正脸,侧脸,添加不同的分数,最终选择分数最大的一个
ReId 复验
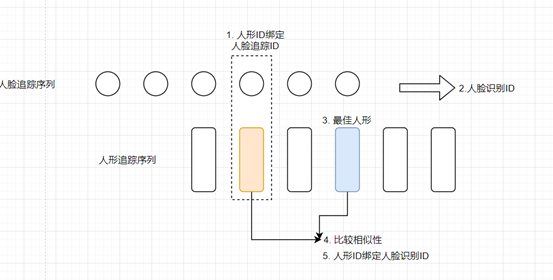
存储人形 ID 绑定人脸追踪 ID(facewindowID)时的人形,并按照肩膀关键点信息裁切
这个人脸追踪 ID 有了人脸识别 ID
从人形追踪序列中选出最佳人形进行 reid
比较 1.1 和 1.3 两个人形相似性,两个人形特征使用 reid 模型,计算两个特征的余弦距离
若 1.4 计算的余弦距离小于 0.55,则允许人形 ID 绑定人脸识别 ID
解决的场景:一个大人在抱小孩,将小孩的脸与大人的身子匹配上了
保存绑定人脸时刻的人形 Humanoid1 和这一个人形序列的最佳人形 Humanoid2,计算两个特征的余弦距离
活体检测
正脸注册时,要求该脸和置信度大于 0.70 的人形框有 iou
要求该帧的存在置信度大于 0.70 的人形检测结果,要注意这个结果要进行复用(由于 yolo 的隔帧检测)
用于人脸注册
存在的问题:有一张人脸的图片送入检测,可以检测到人脸但检测不到人形(人的头像相片),这种情况下会出现误注册的情况,所以要进行活体检测,需要这一张人脸同时有 yolo 的检测结果才可以认为是人
这些是检测出的人脸帧,但是并不是人,调整之后 yolo 没有人的检测结果,可以规避这种假人脸被注册的情况
表情识别
要求人脸的大小不能太小
加载人脸库速度过慢
注册的人脸有 60 张,处理单帧图像的情况下:
- A) 加载人脸库首先需要加载用户 id(耗时 1s)
- B) 通过用户 id 获取 Face 再转化为 app 层可用数据(耗时 1s)
- 解决办法
- 问题 A:通过将人脸库的 id 加载后放入缓存。(1ms)
- 问题 B:获取人脸库的人脸的目的是为了做识别,在识别过程中只需用到人脸的 feature(大小为 512 的 FloatArray),无需用到展示用的人脸图(较大)。将每张人脸的 feature 放入缓存中做识别,需要上报事件的时候再读取该人脸 id 的人脸图就行了。
- 原本处理一帧需要 2 秒,现在只需 1ms。(几乎没有带来什么内存消耗)
视频管线计算的素材冗余
目前视频管线计算的一切素材都与人(宠物)有关,在计算的过程中发现声音、灯光变换就会引起设备告警,从而将视频送到 App 中计算(即使没有人)。且视频长度都不短,考虑到视频计算管线只会优先计算关键帧,而关键帧间隔大约为 2s 的情况下,一段 5 分钟的视频,至少会引起 150 次计算,考虑到帧的解码和唤醒模型,耗时已经是比较可观。且会影响更有价值的素材的计算。
- 拆分视频管线和音频管线,只将存在人形或宠物检测告警的视频,送给视频计算管线计算。声音类的告警给音频计算管线就可以了。
算法的价值 每个场景有自己的解决方法
给了一个任务 构建整个框架 是个什么流程
任务的难点是什么 为什么会遇到这个问题 边界条件,怎么触发 观察,怎么解决
分析问题,问题怎么产生的,为什么人脸在边界,摄像头在边界有畸变,上下多左右窄
附:选帧策略
连续 30 帧
frames=10
FRAMES_GAP=1
frames=10 FRAME_STORE_INTERVAL=1 iou=0.5 一共 30 帧,间隔 1 帧送入检测, 检测 3 次,准确率 3/7=42.86%
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 3 | ≥90% | 2 |
| <90% | 1 | ||
| 错误 | 4 | ||
| 未识别到 | 1 | 没识别到人 |

FRAMES_GAP=2
frames=10 FRAME_STORE_INTERVAL=2 iou=0.5 一共 60 帧,间隔 2 帧送入检测,准确率 4/8=50.00%,单次 inference 耗时 6-8s, P50
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 4 | ≥90% | 2 |
| <90% | 2 | ||
| 错误 | 4 | ||
| 未识别到 | 0 |
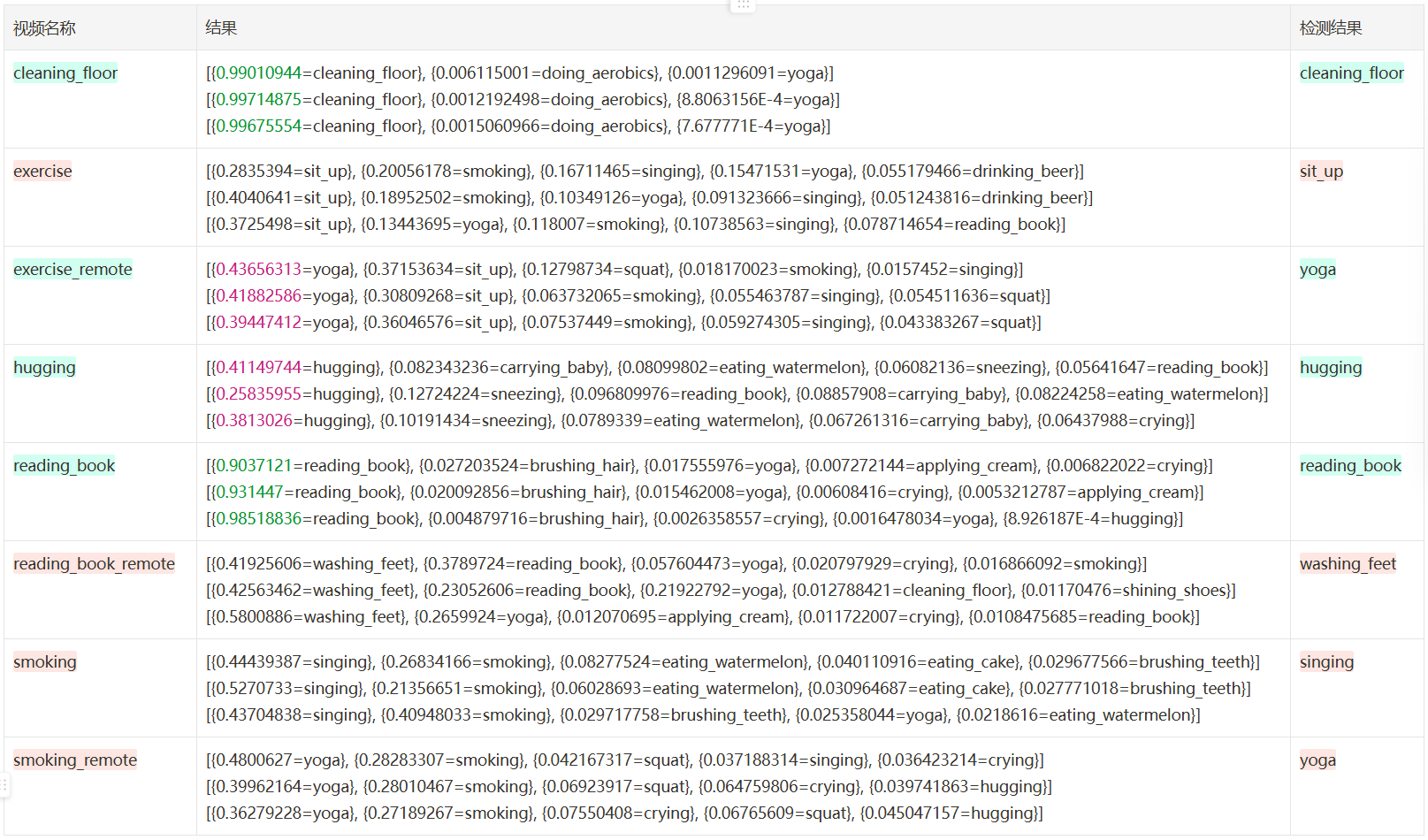
FRAMES_GAP=3
frames=10 FRAME_STORE_INTERVAL=3 iou=0.5 一共 90 帧,准确率 3/8=37.50
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 3 | ≥90% | 2 |
| <90% | 1 | ||
| 错误 | 4 | ||
| 未识别到 | 1 |
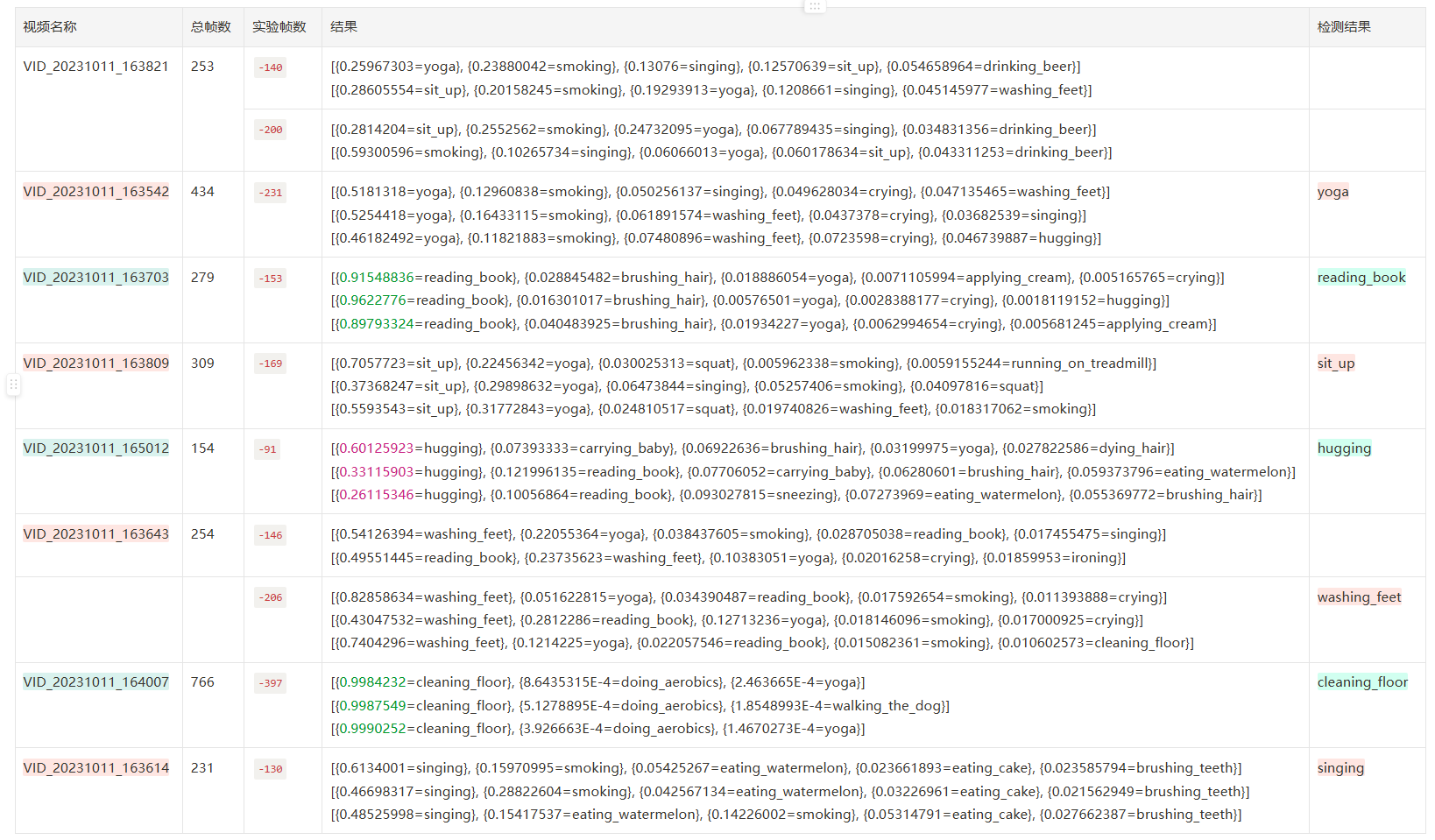
FRAMES_GAP=4
frames=10 FRAME_STORE_INTERVAL=4 iou=0.5 一共 120 帧,准确率 3/8=37.50,单次 inference 耗时 7-8s, P50
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 3 | ≥90% | 2 |
| <90% | 1 | ||
| 错误 | 2 | ||
| 未识别到 | 3 |
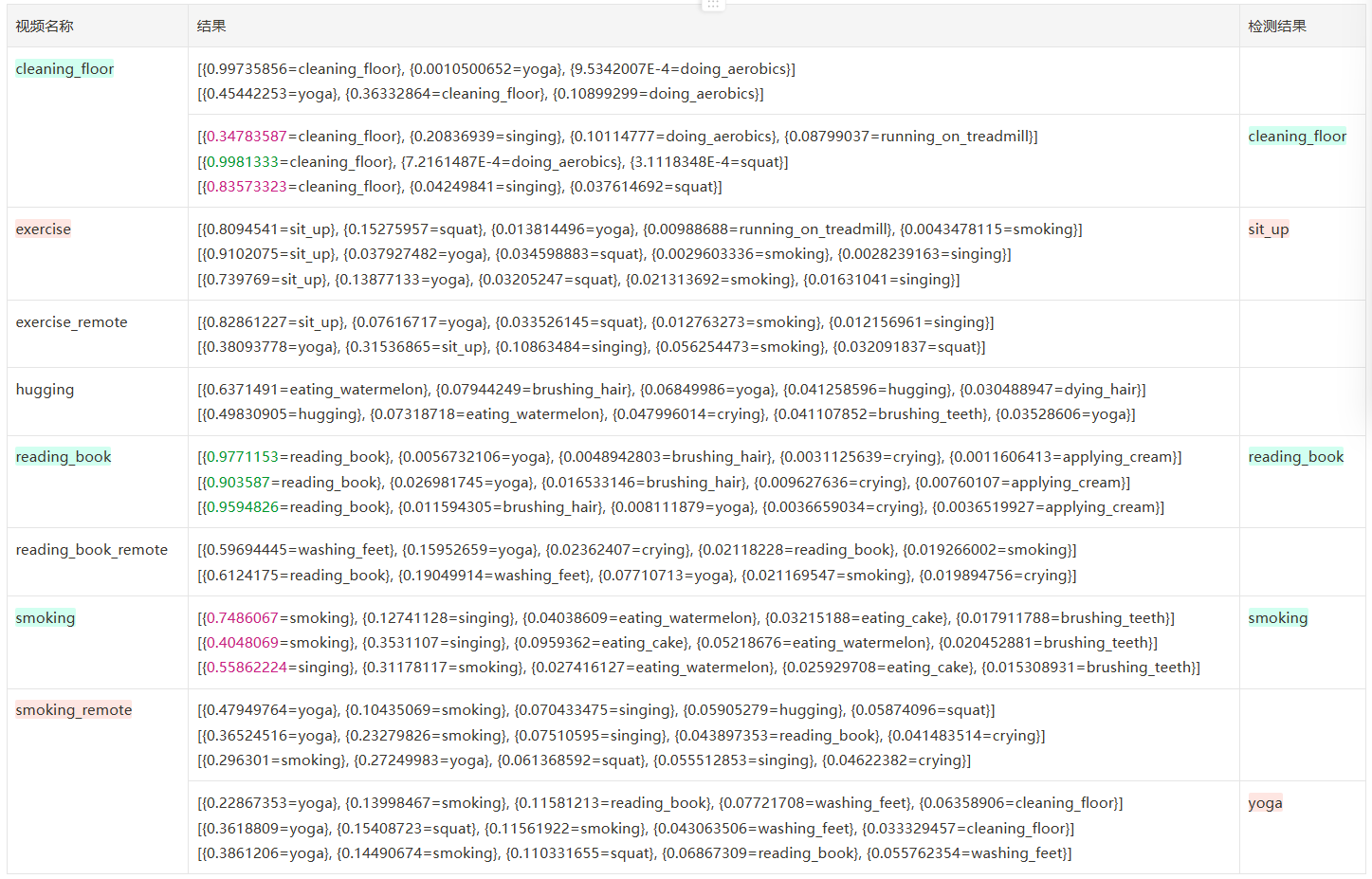
frames=16
FRAMES_GAP=2
frames=16 FRAME_STORE_INTERVAL=3 iou=0.5 一共 96 帧,准确率 4/8=50.00,单次 inference 耗时 9-11s
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 4 | ≥90% | 2 |
| <90% | 2 | ||
| 错误 | 2 | ||
| 未识别到 | 2 |
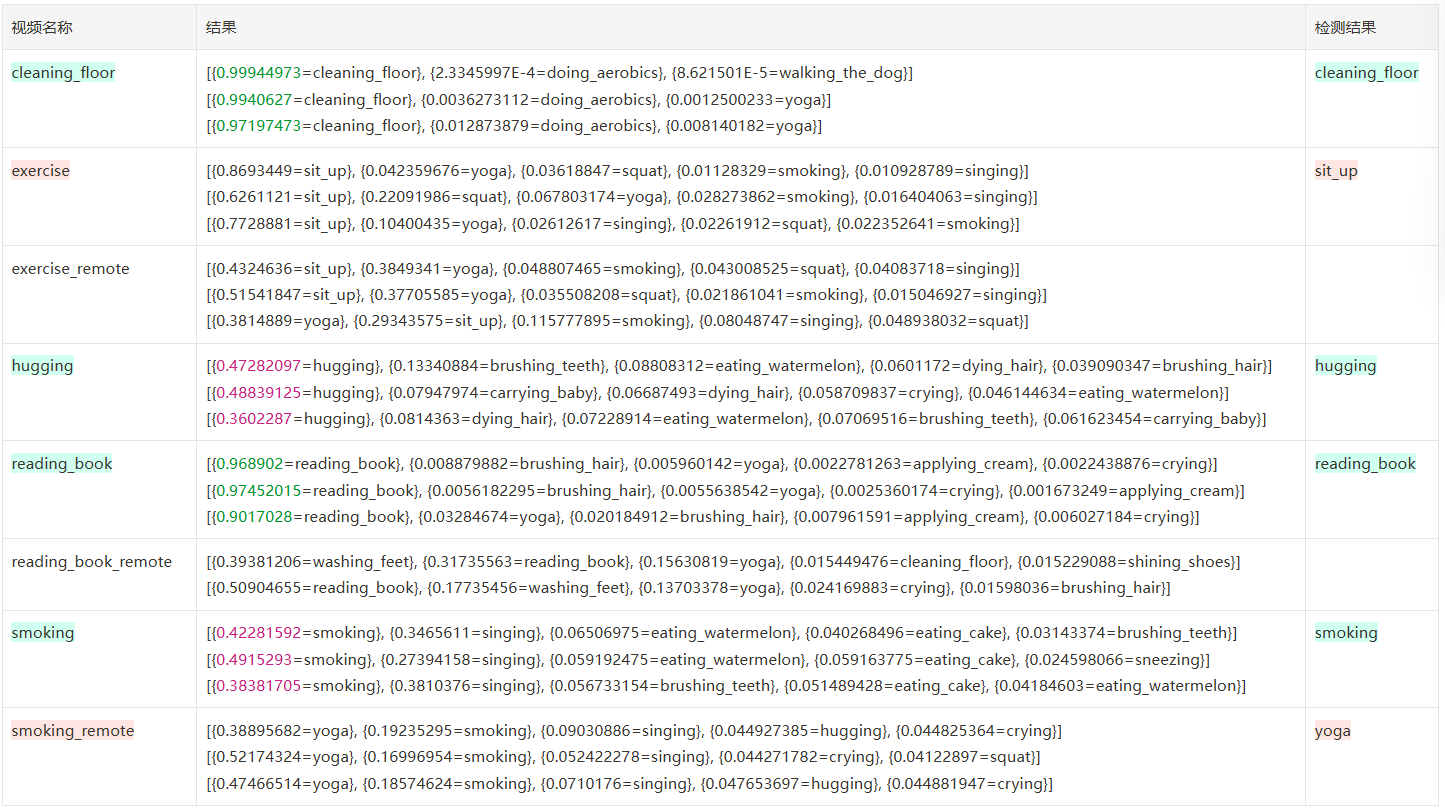
FRAMES_GAP=3
frames=16 FRAME_STORE_INTERVAL=3 iou=0.5 一共 144 帧,准确率 2/8=25.00,单次 inference 耗时 24-10s
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 2 | ≥90% | 1 |
| <90% | 1 | ||
| 错误 | 3 | ||
| 未识别到 | 3 |
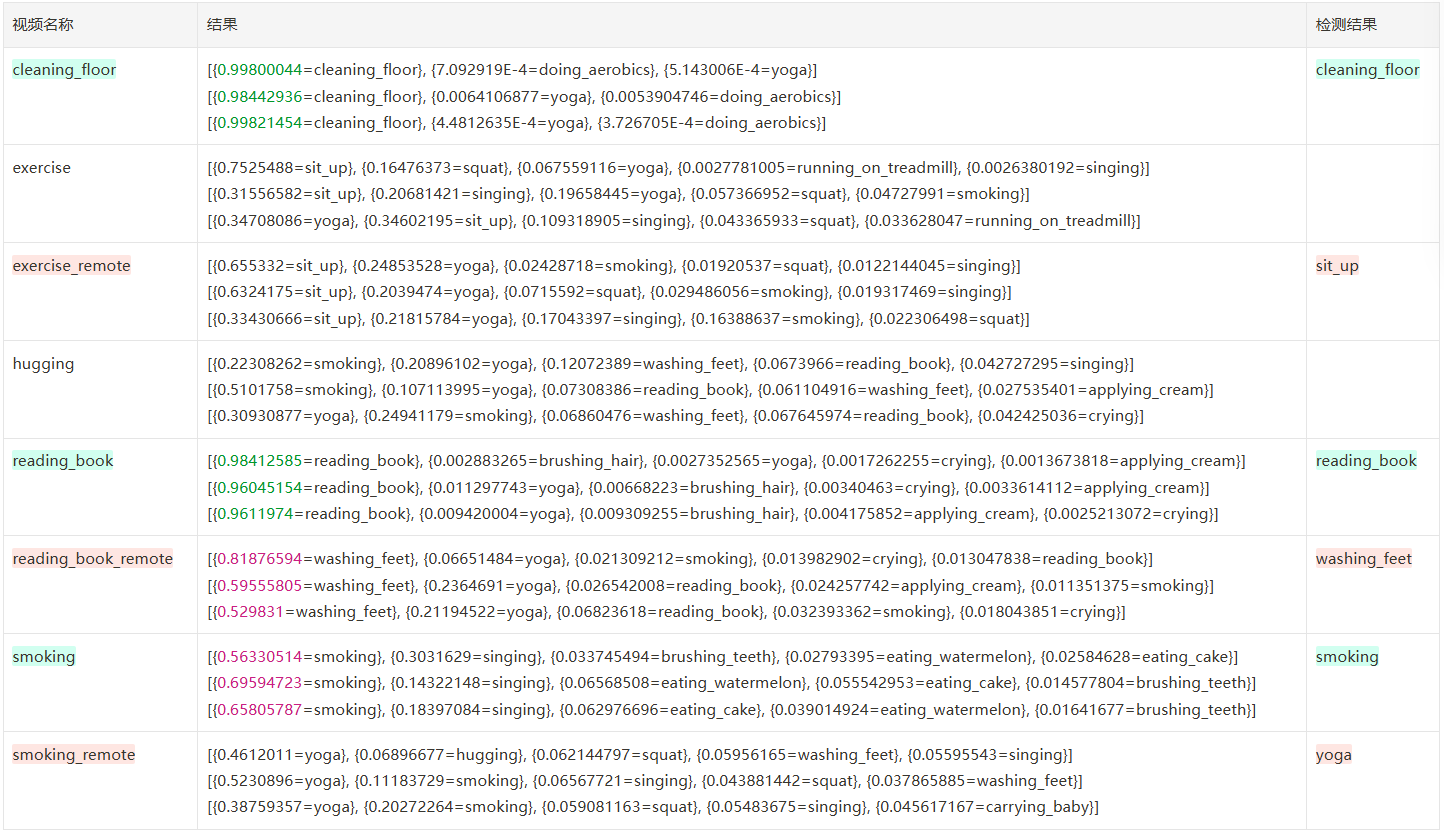
非连续 30 帧
frames=10
FRAMES_GAP=1
从头开始选有人的 30 帧,每连续 10 帧做一次([0,1,2…][10,11,12,…][20,12,22…])
frames=10 FRAME_STORE_INTERVAL=1 iou=0.5 ,准确率 6/9=66.60,单次 inference 耗时 24-30s
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 6 | ≥90% | 3 |
| <90% | 3 | ||
| 错误 | 0 | ||
| 未识别到 | 3 |
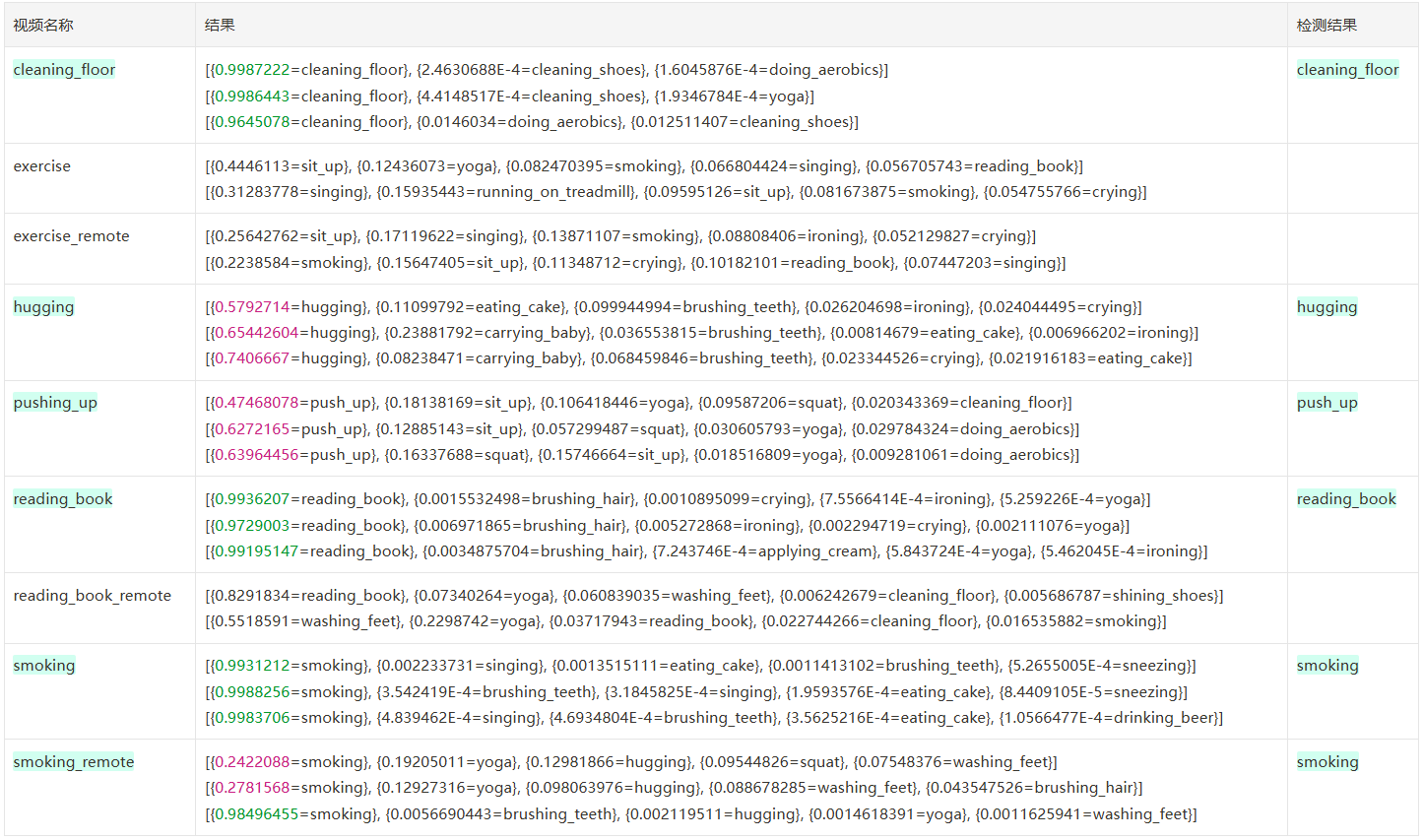
FRAMES_GAP=2
从头开始选有人的 30 帧,每间隔 1 帧选一帧,做三次([0,3,6,…][1,4,7,…][2,5,8…])
frames=10 FRAME_STORE_INTERVAL=2 iou=0.5 ,准确率 7/9=77.70,单次 inference 耗时 24-30s
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 7 | ≥90% | 2 |
| <90% | 5 | ||
| 错误 | 2 | ||
| 未识别到 | 0 |
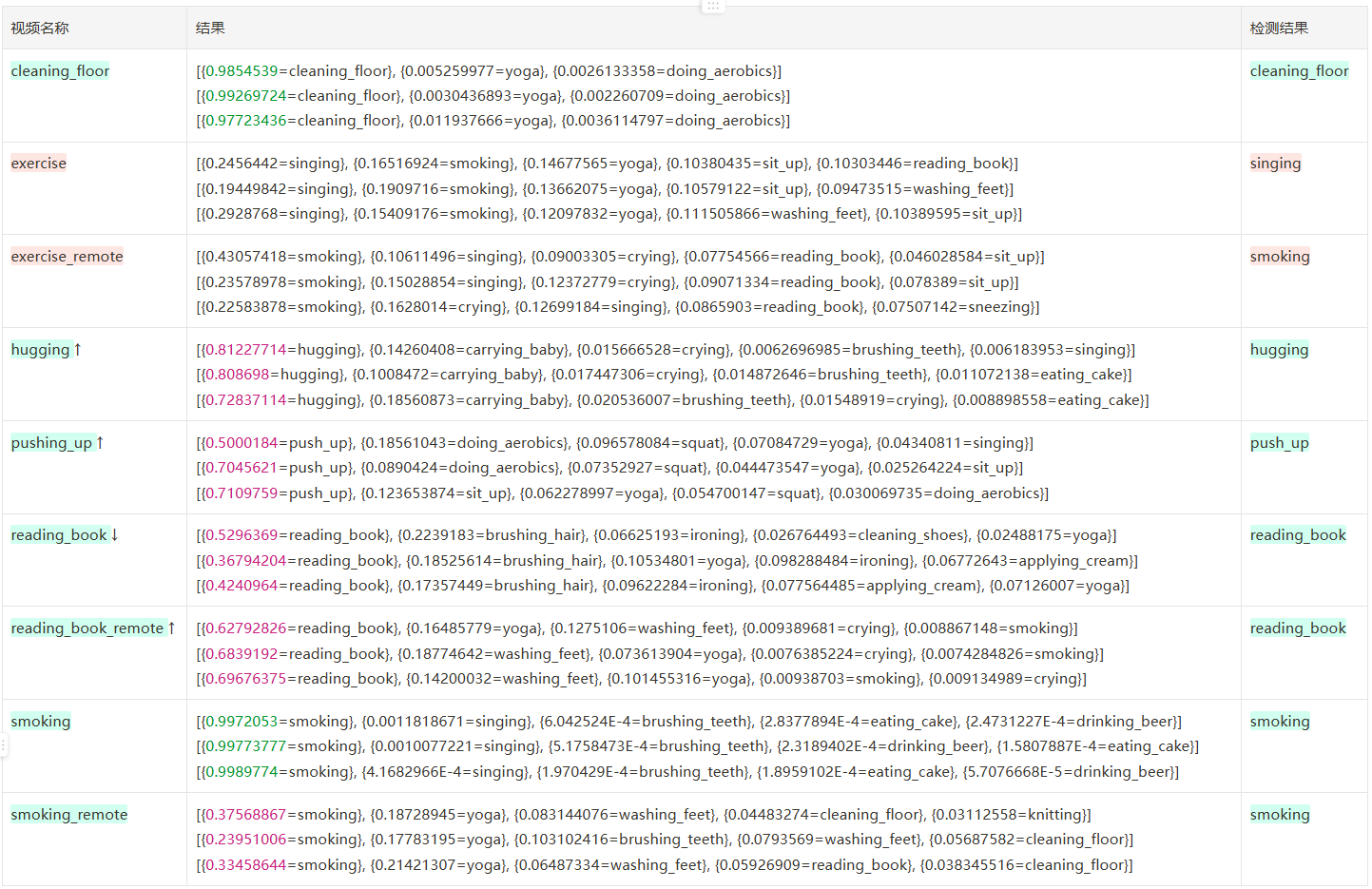
FRAMES_GAP=2 PROCRESS=2
从头开始选有人的 60 帧,每间隔 1 帧加入队列,满 30 帧做三次([0,3,6,…][1,4,7,…][2,5,8…])
frames=10 FRAME_STORE_INTERVAL=3 iou=0.5 ,准确率 4/9=44.40,单次 inference 耗时 24-10s
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 4 | ≥90% | 2 |
| <90% | 2 | ||
| 错误 | 0 | ||
| 未识别到 | 5 |

frames=16
FRAMES_GAP=2
从头开始选有人的 60 帧,每间隔 1 帧加入队列,满 30 帧做 3 次 inference([0,3,6,…][1,4,7,…][2,5,8…])
frames=16 FRAME_STORE_INTERVAL=2 threshold=0.8 ,准确率 5/9=55.50,单次 inference 耗时 24-10s
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 5 | ≥90% | 3 |
| <90% | 2 | ||
| 错误 | 1 | ||
| 未识别到 | 3 |
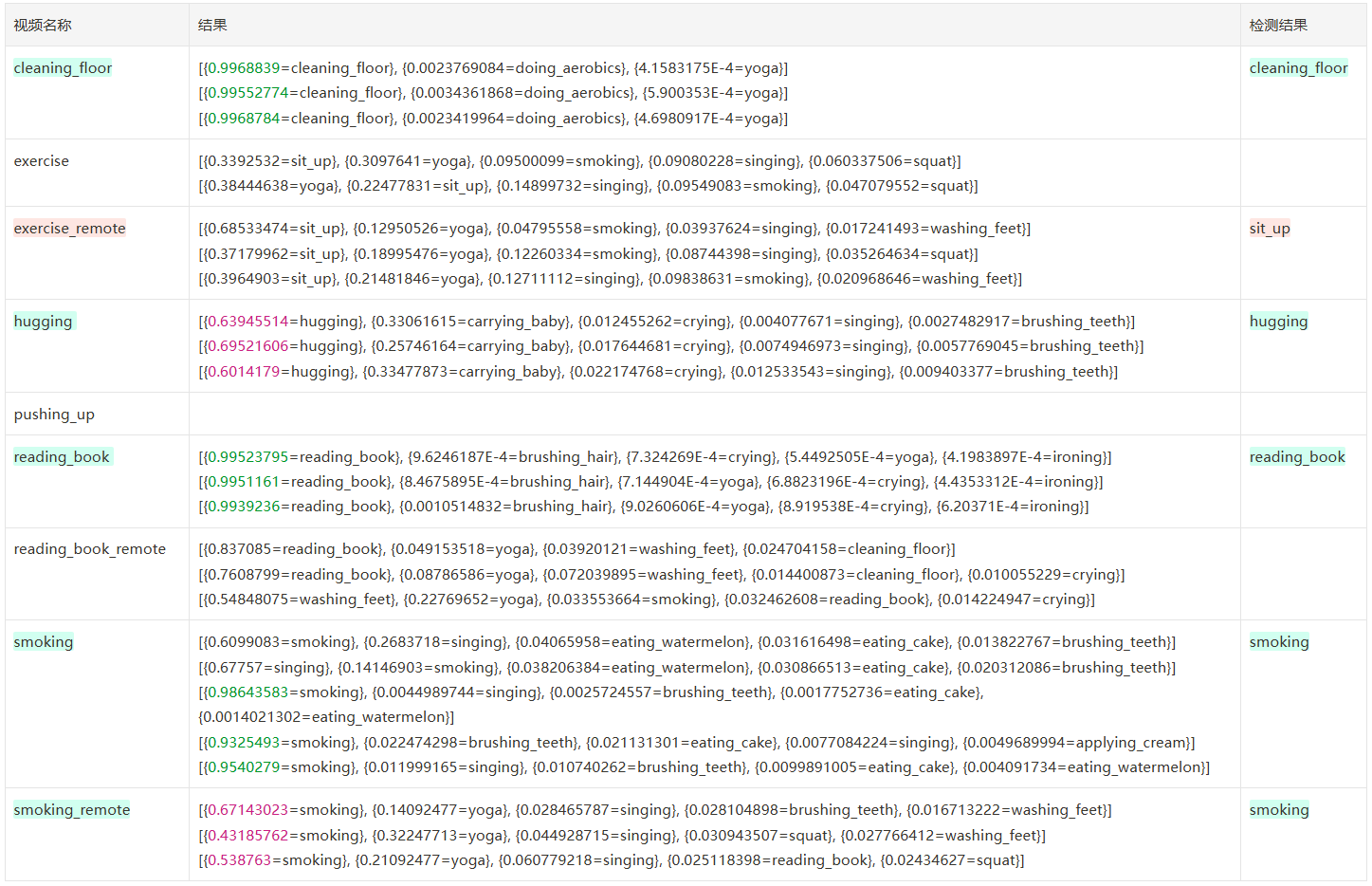
FRAMES_GAP=3 PROCRESS=2
从头开始选有人的 90 帧,每间隔 2 帧加入队列,满 30 帧做 3 次 inference([0,3,6,…][1,4,7,…][2,5,8…])
frames=10 FRAME_STORE_INTERVAL=3 threshold=0.5 ,准确率 3/9=33.30,单次 inference 耗时 24-30s
| 结果 | 个数 | 备注 | |
|---|---|---|---|
| 正确 | 3 | ≥90% | 2 |
| <90% | 1 | ||
| 错误 | 4 | ||
| 未识别到 | 2 |
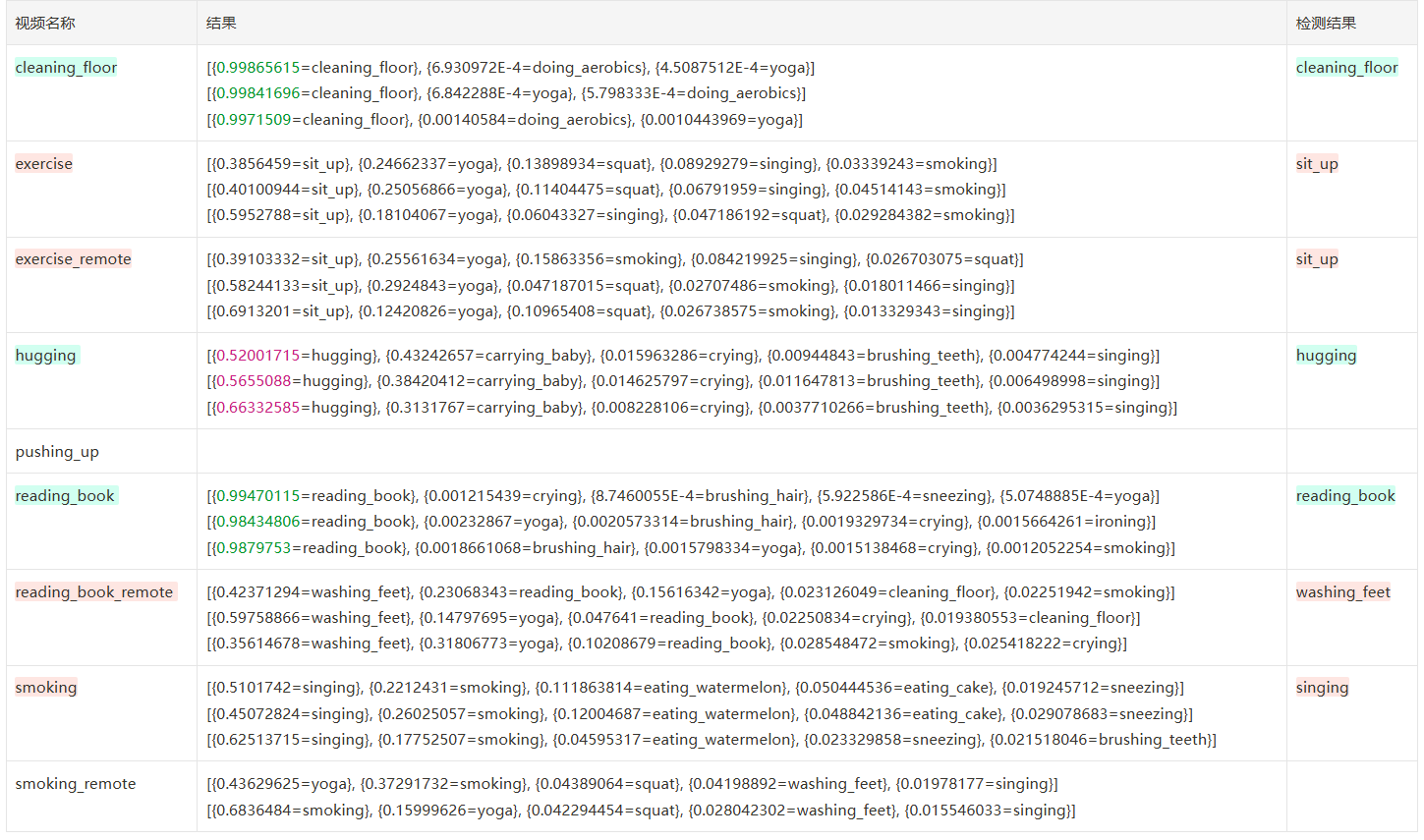
结果