
区别
HashMap 和 HashTable 没有太大的差别,基本就是HashMap 方法没有 synchronized 修饰,线程非安全,HashTable 线程安全;
- HashMap 几乎可以等价于 Hashtable,除了 HashMap 是非 synchronized 的,并可以接受 null(HashMap 可以接受为 null 的键值(key)和值(value),而 Hashtable 则不行)。
1 | //HashMap 的 hash 算法对 null 有特殊处理 -> 赋值为 0 |
HashMap 是非 synchronized,而 Hashtable 是 synchronized,这意味着Hashtable 是线程安全的,多个线程可以共享一个 Hashtable;而如果没有正确的同步的话,多个线程是不能共享 HashMap 的。Java 5 提供了 ConcurrentHashMap,它是 HashTable 的替代,比 HashTable 的扩展性更好。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//HashMap:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
//HashTable
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
//HashTable 重写的计算散列表索引
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}另一个区别是 HashMap 的迭代器(Iterator)是 fail-fast 迭代器,而 Hashtable 的 enumerator 迭代器不是 fail-fast 的。所以当有其它线程改变了 HashMap 的结构(增加或者移除元素),将会抛出 ConcurrentModificationException,但迭代器本身的 remove()方法移除元素则不会抛出 ConcurrentModificationException 异常。但这并不是一个一定发生的行为,要看 JVM。这条同样也是 Enumeration 和 Iterator 的区别。
由于 Hashtable 是线程安全的也是 synchronized,所以在单线程环境下它比 HashMap 要慢。如果不需要同步,只需要单一线程,那么使用 HashMap 性能要好过 Hashtable。
HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
要注意的一些重要术语
sychronized 意味着在一次仅有一个线程能够更改 Hashtable。就是说任何线程要更新 Hashtable 时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新 Hashtable。
Fail-safe 和 iterator 迭代器相关。如果某个集合对象创建了 Iterator 或者 ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出 ConcurrentModificationException 异常。但其它线程可以通过 set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用 set()方法,将会抛出 IllegalArgumentException 异常。
结构上的更改指的是删除或者插入一个元素,这样会影响到 map 的结构。
能否让 HashMap 同步?
HashMap 可以通过下面的语句进行同步:
1 | Map m = Collections.synchronizeMap(hashMap); |
HashTable 算是一种被淘汰的存储结构,几乎被 HashMap 替换,如果不是因为有兼容代码必须使用 HashTable,理应不再使用,就算因为线程安全也有 ConcurrentHashMap 而不是继续使用 HashTable
HashMap 底层实现
数组+链表实现,初始链表大小为 8,链表超过 8 转变为红黑树
- put 一个数据时,计算 key 的 hash 值,⼆次 hash 然后对数组⻓度取模,对应到数组下标,
- 如果没有产⽣ hash 冲突(下标位置没有元素),则直接创建 Node 存⼊数组,
- 如果产⽣ hash 冲突(链表有数据),先进⾏ equal()⽐较,相同则取代该元素,不同,则是追加到链表末尾(jdk1.8)
- 链表⾼度达到 8(储存值数量到达 8),则转变为红⿊树,⻓度低于 6 则将红⿊树转回链表
- 也就是超过 8 就不存在链表了,只剩下数组+红黑树
- 转变为红⿊树也是可能因为防止有些人搞事情,跑来攻击,整成很长的链表,搞成红黑树去查询就没问题了
- key 为 null,存在下标 0 的位置(null 的 hash 值特殊处理)
- 链表主要是用来解决 hash 冲突的
解决哈希冲突
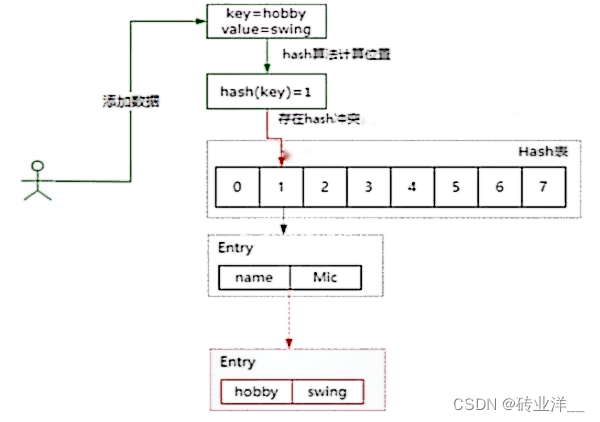
HashMap 底层是采用数组结构来存储数据元素,数组的默认长度是 16,当我们通过 put 方法去添加数据的时候,HashMap 会根据 key 的 hash 值进行取模运算,最终把这样一个值保存到数组的指定位置。
但是这样的设计方式会存在 hash 冲突的问题,也就是两个不同的 hash 值的 key,取模后会落到同一个数组下标,所以 HashMap 引入了一个链式寻址法来解决 hash 冲突的问题。也就是说对于存在冲突的 key,HashMap 把这些 key 组成一个单向链表,然后采用尾插法把这样一个 key 保存到链表的一个尾部,另外,为了避免链表过长导致查询效率下降,所以当链表长度大于 8 并且数组长度大于等于 64 的时候,HashMap 会把当前链表转换为红黑树,从而去减少链表数据查询的时间复杂度来提升查询效率。
链地址法(Separate Chaining)
在链地址法中,每个哈希桶(槽位)都维护一个链表(或其他数据结构,如红黑树),当发生哈希冲突时,新的元素被添加到相应槽位的链表中。这样,同一个槽位上的元素形成了一个链表,可以通过链表来存储具有相同哈希值的多个元素。
基本思想:
- 插入操作: 当需要插入一个新元素时,首先计算其哈希值,然后定位到相应的哈希桶。如果该桶为空,直接插入;如果不为空,将新元素添加到链表的末尾。
- 查找操作: 查找时同样计算哈希值并定位到相应的哈希桶,然后在链表中查找目标元素。
- 删除操作: 删除操作也需要先找到对应的哈希桶,然后在链表中删除目标元素。
这种方法的优势在于它相对简单,易于实现,而且可以有效地处理大量的哈希冲突。然而,性能取决于链表的长度,当链表变得过长时,可能会降低查找效率。在实际应用中,一些哈希表实现可能会在链表长度达到一定阈值时,转换为更高效的数据结构,如红黑树,以提高性能。
把存在 hash 冲突的 key, 以单向链表的方式来存储,存在冲突的 key 直接以单向链表的方式进行存储
红黑树
- 红黑树因为排序过,通过左旋右旋查找快
- 当数据很多很多的时候用树结构去增删改查会贼快
- 数据很多时,树结构是一种非常优秀的结构
HashMap 的初始容量
- 初始数组大小 16 -> DEFAULT_INITIAL_CAPACITY = 1 << 4;
- 初始链表大小 8 -> TREEIFY_THRESHOLD = 8;
- 初始加载因子 0.75 -> DEFAULT_LOAD_FACTOR = 0.75f;
- 初始树型容量 64 -> MIN_TREEIFY_CAPACITY = 64;
如果 HashMap 的大小超过了负载因子(load factor)定义的容量,怎么办?
- 默认的负载因子大小为 0.75
- 也就是说,当一个 map 填满了 75%的 bucket 时候,和其它集合类(如 ArrayList 等)一样,将会创建原来 HashMap 大小的两倍的 bucket 数组,来重新调整 map 的大小,并将原来的对象放入新的 bucket 数组中。
- 负载因子在 0.7 左右最好,扩容很多结构对象都是扩容 2 倍大差不差
- 因为 2 的倍数用二进制表示是只有一个 1 其他都是 0 的一串数字,之后运算方便
- 0001,0010,0100,1000, 1 0000
HashMap 扩容原理
(当数组大小 > 加载因子 * 数组长度)时,HashMap 会触发扩容
如果 HashMap 是键值对数据大于阀值,容量翻倍(数据个数大于阀值扩容)
如果 HashMap 中链表长度大于等于 8 时(链表长度大于 8 时扩容)
- 此时不会立即转换为树,而是先判断数组容量是否大于 6
- 如果数组容量是 16 或 32,进行一次扩容
- 使用扩容重新调整数据的存放位置来缩短链表长度
1
2
3if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY){
newThr = oldThr << 1; // 2 倍
}- 此时不会立即转换为树,而是先判断数组容量是否大于 6
旧散列的数据迁移到新的散列中,做了一个位运算 e.hash & oldCap 判断链表是否也要改变位置,新的索引位置 = 旧的位置 + 旧的数组长度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 当 node 的 hash 值 & 旧容量位 == 0 时,这个数据是不需要换桶位置的
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 当 hash 值 & 旧容量位 != 0 时,这个数据是需要换位置的,而且换的位置为:旧桶的位置 + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
HashMap 在高并发下,会出现环形链表?
jdk1.7 map 采用链表头节点插入,多线程扩容会出现环形链表
jdk1.8 map 采用链表尾节点插入(永远向后,不会产生回环),多线程扩容不会出现环形链表
HashMap 的线程不安全主要体现哪里?
在 JDK1.7 中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
在 JDK1.8 中,在并发执行 put 操作时会发生数据覆盖的情况。
HashMap 的 put()方法中,有 modCount++的操作,即调用 put()时,修改次数加 1,“i++”操作,从表面上看 i++ 只是一行代码,但实际上它并不是一个原子操作,它的执行步骤主要分为三步,而且在每步操作之间都有可能被打断。
1 | 第一个步骤是: 读取; |
从源码的角度,或者说从理论上来讲,证明 HashMap 是线程非安全的。因为如果有多个线程同时调用 put() 方法的话,它很有可能会把 modCount 的值计算错。
1 | ++modCount; |