
- 线程池的种类⭐⭐⭐⭐⭐
- 线程池的优点⭐⭐⭐⭐
- 平时当中使用案例⭐⭐⭐⭐
- ThreadPoolExecutor⭐⭐
为何要使用线程池,有何优点
平时的安卓开发中,很多耗时操作不能在主线程中执行,不然就会阻塞主线程,因此我们常见的做法是new 一个Thread来执行耗时操作,最后通过Handler切换到主线程来修改UI。然而当线程数量多的时候,有可能会导致死机和OOM。可以使用线程池来管理我们所创建的线程。所谓线程池就是事先创建一系列线程,把它们放在一个容器里,使用的时候直接从池子里拿线程,而不需要重新去new一个。
线程池其实是一种池化的技术实现,池化技术的核心思想就是实现资源的复用,避免资源的重复创建和销毁带来的性能开销。线程池可以管理一堆线程,让线程执行完任务之后不进行销毁,而是继续去处理其它线程已经提交的任务。
使用线程池的好处:
- 多个线程可以多次复用,避免因线程频繁创建和销毁给系统带来的损耗,同时也可以提高系统响应速度,当任务需要执行时不需要创建新的线程就可以执行;
- 线程池的最大并发数可控制,避免大量的线程之间因互相抢占系统资源而导致的阻塞现象;
- 能够对线程进行管理,并提供定时执行以及定间隔循环执行等功能;
ThreadPoolExecutor
构造函数
ThreadPoolExecutor:
1 | // 构造函数 |
corePoolSize:线程池的核心线程数量。核心线程当该线程处于闲置时间也不会回收的线程。可以执行threadPoolExecutor.allowCoreThreadTimeOut(true)后,当闲置的核心线程的等待新任务时间超过了keepAliveTime也会被终止;maximumPoolSize:线程池最大线程数,等于核心线程 + 非核心线程。如果运行的线程总数量超过这个数值,那么接下里新来的任务都会阻塞等待;keepAliveTime:闲置的非核心线程等待时间超过keepAliveTime设定的时间就会被回收,而核心线程需要执行threadPoolExecutor.allowCoreThreadTimeOut(true)后超过时间才会被回收;unit:keepAliveTime的单位:单位 含义 TimeUnit.DAYS 天 TimeUnit.HOURS 时 TimeUnit.MINUTES 分 TimeUnit.MILLISECONDS 毫秒 TimeUnit.MICROSECONDS 微秒 TimeUnit.NANOSECONDS 纳秒 workQueue:执行execute()添加的任务所存放的工作阻塞队列,有以下选项:
阻塞队列 | 说明 |
| —– | —– |
| ArrayBlockingQueue | 基于数组实现的有界的阻塞队列,该队列按照FIFO(先进先出)原则对队列中的元素进行排序。 |
| LinkedBlockingQueue | 基于链表实现的阻塞队列,该队列按照FIFO(先进先出)原则对队列中的元素进行排序。 |
| SynchronousQueue | 内部没有任何容量的阻塞队列。在它内部没有任何的缓存空间。对于SynchronousQueue中的数据元素只有当我们试着取走的时候才可能存在。 |
| PriorityBlockingQueue | 具有优先级的无限阻塞队列。|threadFactory:从名字直接翻译就知道是“线程工厂”,用于新线程的创建,默认为Executors.defaultThreadFactory();handler:RejectedExecutionHandler对象,该对象只是一个接口类,里面只有一个rejectedExecution方法。如果当前的活动线程达到maximumPoolSize或者执行任务失败了,就会执行rejectedExecution()。在ThreadPoolExecutor有四个内部类实现了rejectedExecution()方法,代表四种不同的处理方式:可选值 说明 CallerRunsPolicy 只用调用者所在线程来运行任务。 AbortPolicy 直接抛出RejectedExecutionException异常。 DiscardPolicy 丢弃掉该任务,不进行处理。 DiscardOldestPolicy 丢弃队列里最近的一个任务,并执行当前任务。
2.2 线程池工作原理
线程池的工作原理涉及核心线程、非核心线程、阻塞队列等,当有新的任务加入线程池时,池内工作原理具体如下:
- 当正在运行的线程数 < 核心线程数,马上创建核心线程处理这个任务;
- 当正在运行的线程数 >= 核心线程数,把该任务加入阻塞队列;
- 当阻塞队列满了且正在运行的线程数 < 线程池最大线程数,则创建新的非核心线程来处理该任务;
- 当阻塞队列满了且正在运行的线程数 >= 线程池最大线程数,则线程池调用handler的reject方法拒绝本次新任务添加。
线程池的种类和特点
Android中的线程池都是直接或间接通过配置ThreadPoolExecutor来实现不同特性的线程池。在Android中最常见的4种线程池分别为FixThreadPool、CachedhreadPool、SingleThreadPool、ScheduleThreadExecutr.
FixThreadPool
1 | public static ExecutorService newFixedThreadPool(int nThreads) { |
- 线程数量固定的线程池,只有核心线程(因为corePoolSize = maximumPoolSize),如果线程池的线程处于空闲状态的话,这些核心线程也不会被回收,所以FixThreadPool也可以更快速地响应外界请求;
- 如果所有线程都在忙碌状态,如果有新的任务到来就会处于等待状态,而不会创建新的线程来执行;
- 适用于很稳定、很正规的并发线程,多用于服务器;
SingleThreadPool
1 | public static ExecutorService newSingleThreadExecutor() { |
单例线程池,任意时间内池中只有一个线程。因此,当有一个线程正在执行时,其他的任务都需要在任务队列里等待。
CachedThreadPool
1 | public static ExecutorService newCachedThreadPool() { |
无界可自动回收线程池,其中无界体现在maximumPoolSize设置为Integer.MAX_VALUE,Integer.MAX_VALUE代表很大的数,因此可以理解为无界限。可回收是因为核心线程数设置为0,超时时间设置为60秒,因此该线程池里所有的线程一旦处于闲置时间超过60秒就会被自动回收了。因此这种线程池有以下特点:
- 任何任务立即被执行;
- 闲置时不占系统资源;
- 适合执行大量的耗时较少的任务;
ScheduledThreadPool
1 | public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { |
周期任务线程池,核心线程数固定,非核心线程则没有限制数量,非核心线程闲置时立刻回收。适合执行定时任务以及有固定周期的重复任务。
总结
| 类型 | 创建方法 | 说明 |
|---|---|---|
| FixedThreadPool | Executors.newFixedThreadPool(int nThreads) | 线程数固定的线程池,只有核心线程,并且不会被回收,没有超时机制 |
| CachedThreadPool | Executors.newCachedThreadPool() | 无界可自动回收线程池,只有非核心线程,闲置线程超过60秒自动回收 |
| ScheduledThreadPool | Executors.newScheduledThreadPool(int corePoolSize) | 周期任务线程池,核心线程数固定,非核心线程数无限制,非核心线程闲置时立刻回收 |
| SingleThreadExecutor | Executors.newSingleThreadExecutor() | 单例线程池,确保所有任务在同一线程中按顺序执行 |
实际使用案例
1 | mXRExecutorService = Executors.newFixedThreadPool(THREAD_NUMBS); |
Dispatchers.Default 是如何调度的?
Dispatchers.Default 使用
1 | GlobalScope.launch(Dispatchers.Default) { |
开启协程,指定其运行的任务类型为:Dispatchers.Default。
此时launch函数闭包里的代码将在线程池里执行。
Dispatchers.Default 用在计算密集型的任务场景里,此种任务比较吃CPU。
Dispatchers.Default 原理
概念约定
在解析原理之前先约定一个概念,如下代码:
1 | GlobalScope.launch(Dispatchers.Default) { |
在任务里执行线程的睡眠操作,此时虽然线程处于挂起状态,但它还没执行完任务,在线程池里的状态我们认为是忙碌的。
再看如下代码:
1 | GlobalScope.launch(Dispatchers.Default) { |
当任务执行结束后,线程继续查找任务队列的任务,若没有任务可执行则进行挂起操作,在线程池里的状态我们认为是空闲的。
调度原理
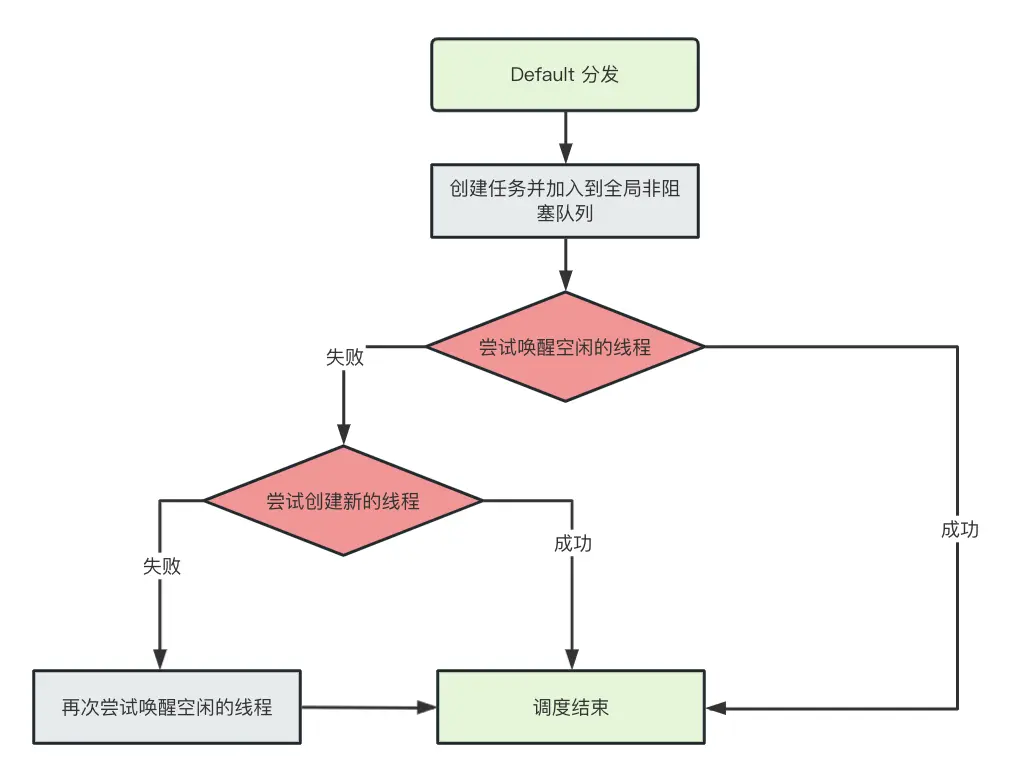
注:此处忽略了本地队列的场景
- launch(Dispatchers.Default) 作用是创建任务加入到线程池里,并尝试通知线程池里的线程执行任务
- launch(Dispatchers.Default) 执行并不耗时
Dispatchers.IO是如何调度的?
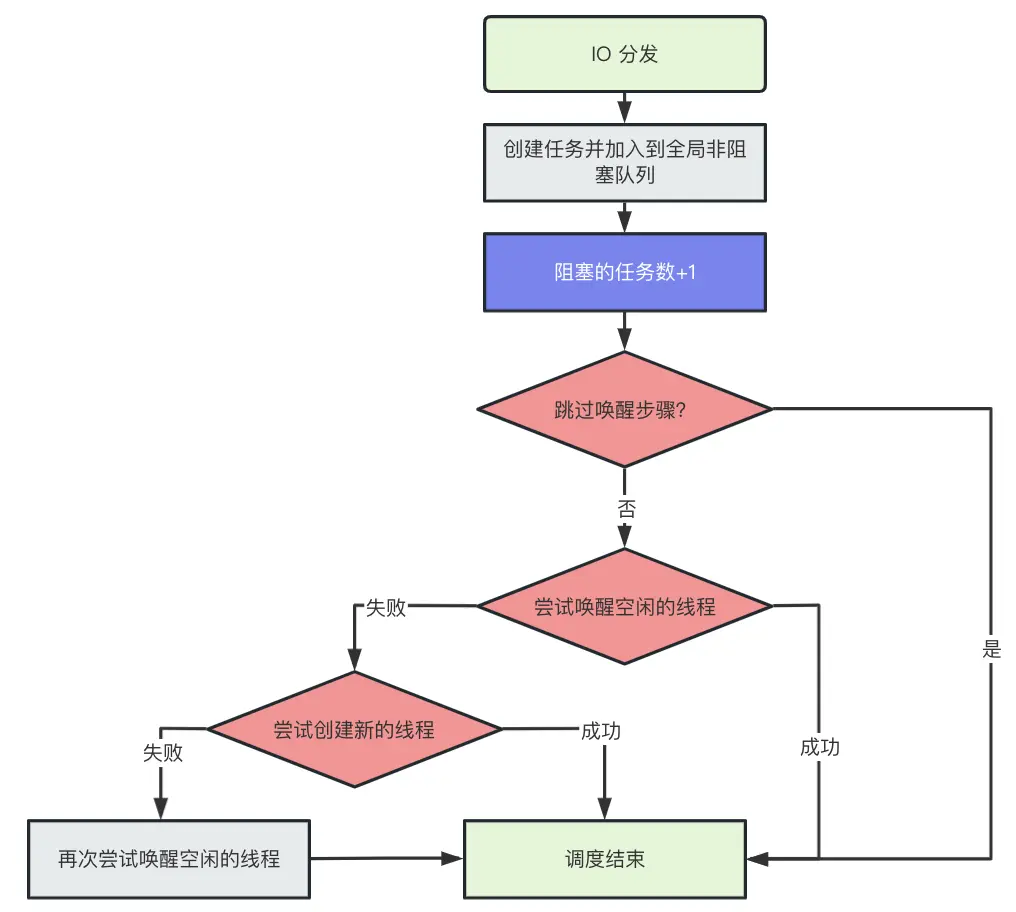
Dispatchers.Default的调度很相似,其中标蓝的流程是重点的差异之处。
结合Dispatchers.Default和Dispatchers.IO调度流程可知影响任务执行的步骤有两个:
- 线程池是否有空闲的线程
- 创建新线程是否成功
先分析第2点,源码:
1 | #CoroutineScheduler |
举个例子:
假设核心线程数为8,初始时创建了8个Default线程,并一直保持忙碌。此时分别使用Dispatchers.Default 和 Dispatchers.IO提交任务,看看有什么效果。
- Dispatchers.Default 提交任务,此时线程池里所有任务都在忙碌,于是尝试创建新的线程,而又因为当前计算型的线程数=8,等于核心线程数,此时不能创建新的线程,因此该任务暂时无法被线程执行
- Dispatchers.IO 提交任务,此时线程池里所有任务都在忙碌,于是尝试创建新的线程,而当前阻塞的任务数为1,当前线程池所有线程个数为8,因此计算型的线程数为 8-1=7,小于核心线程数,最后可以创建新的线程用以执行任务
这也是两者的最大差异,因为对于计算型(非阻塞)的任务,很占CPU,即使分配再多的线程,CPU没有空闲去执行这些线程也是白搭,而对于IO型(阻塞)的任务,不怎么占CPU,因此可以多开几个线程充分利用CPU性能。
线程池是如何调度任务的?
不论是launch(Dispatchers.Default) 还是launch(Dispatchers.IO) ,它们的目的是将任务加入到队列并尝试唤醒线程或是创建新的线程,而线程寻找并执行任务的功能并不是它们完成的,这就涉及到线程池调度任务的功能。
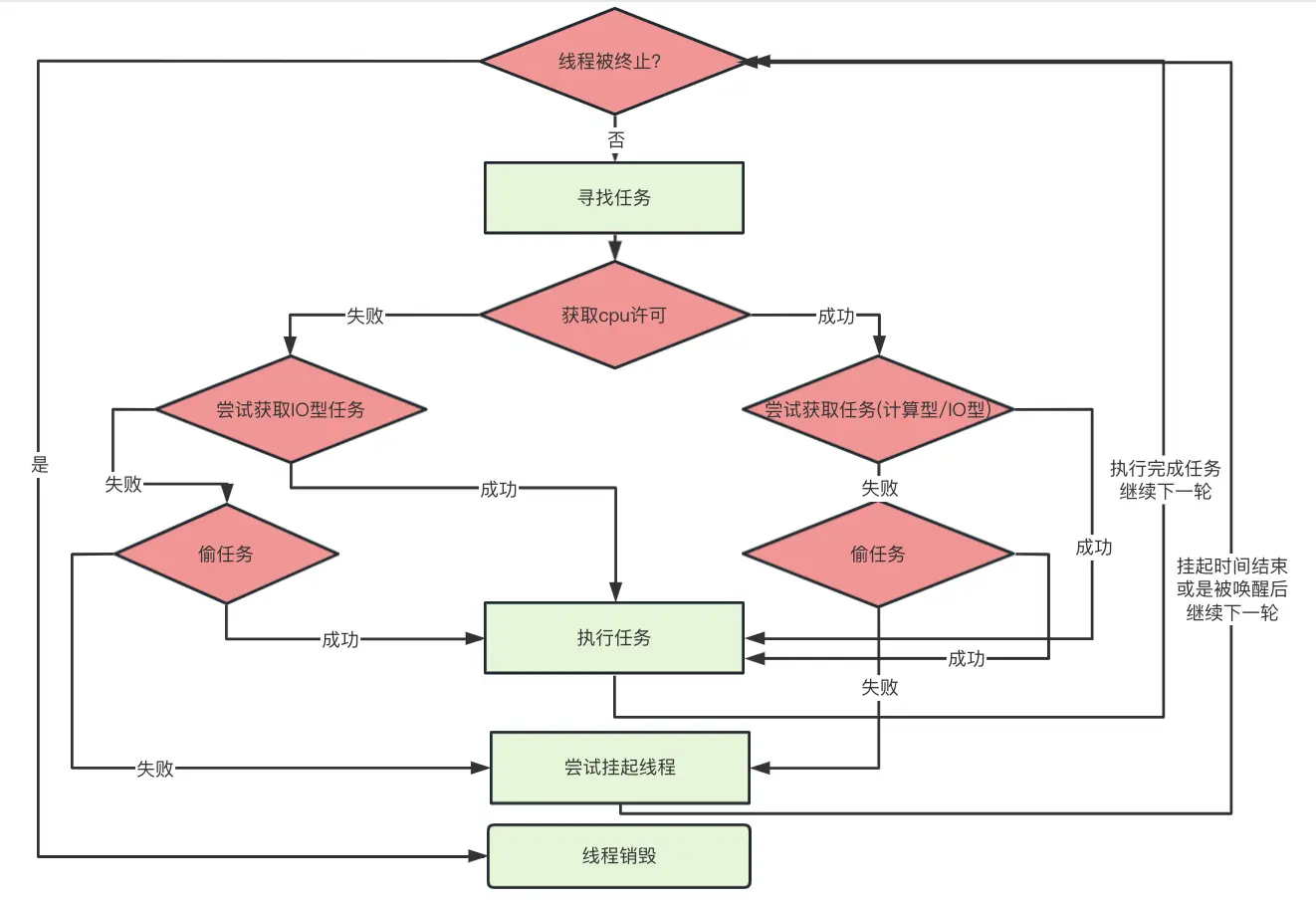
线程池里的每个线程都会经历上图流程:
- 只有获得cpu许可的线程才能执行计算型任务,而cpu许可的个数就是核心线程数
- 如果线程没有找到可执行的任务,那么线程将会进入挂起状态,此时线程即为空闲状态
- 当线程再次被唤醒后,会判断是否已经被终止,若是则退出,此时线程就销毁了
处在空闲状态的线程被唤醒有两种可能:
- 线程挂起的时间到了
- 挂起的过程中,有新的任务加入到线程池里,此时将会唤醒线程
Dispatchers.Default 任务会阻塞?该怎么办?
假设我们的设备有8核。
先开启8个计算型任务:
1 | binding.btnStartThreadMultiCpu.setOnClickListener { |
每个任务里线程睡眠了很长时间。
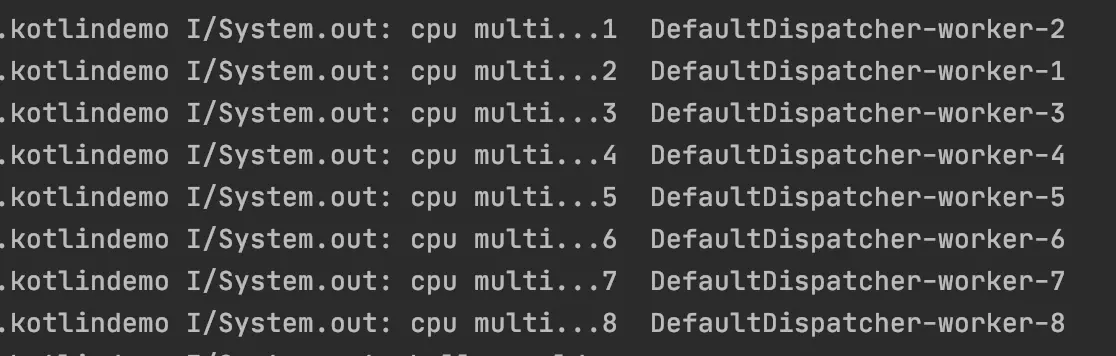
从打印可以看出,8个任务都得到了执行,且都在不同的线程里执行。
此时再次开启一个计算型任务:
1 | var singleCpuCount = 1 |
没有任何打印,新加入的任务没有得到执行。
既然计算型任务无法得到执行,尝试换为IO任务:
1 | var singleIoCount = 1 |
这次有打印了,说明IO任务得到了执行,并且是新开的线程。

- 计算密集型任务能分配的最大线程数为核心的线程数(默认为CPU核心个数,比如我们的实验设备上是8个),若之前的核心线程数都处在忙碌,新开的任务将无法得到执行
- IO型任务能开的线程默认为64个,只要没有超过64个并且没有空闲的线程,那么就一直可以开辟新线程执行新任务
:Dispatchers.Default 不要用来执行阻塞的任务,它适用于执行快速的、计算密集型的任务,比如循环、又比如计算Bitmap等。
线程的生命周期是如何确定
是什么决定了线程能够挂起,又是什么决定了它唤醒后的动作?
先从挂起说起,当线程发现没有任务可执行后,它会经历如下步骤:
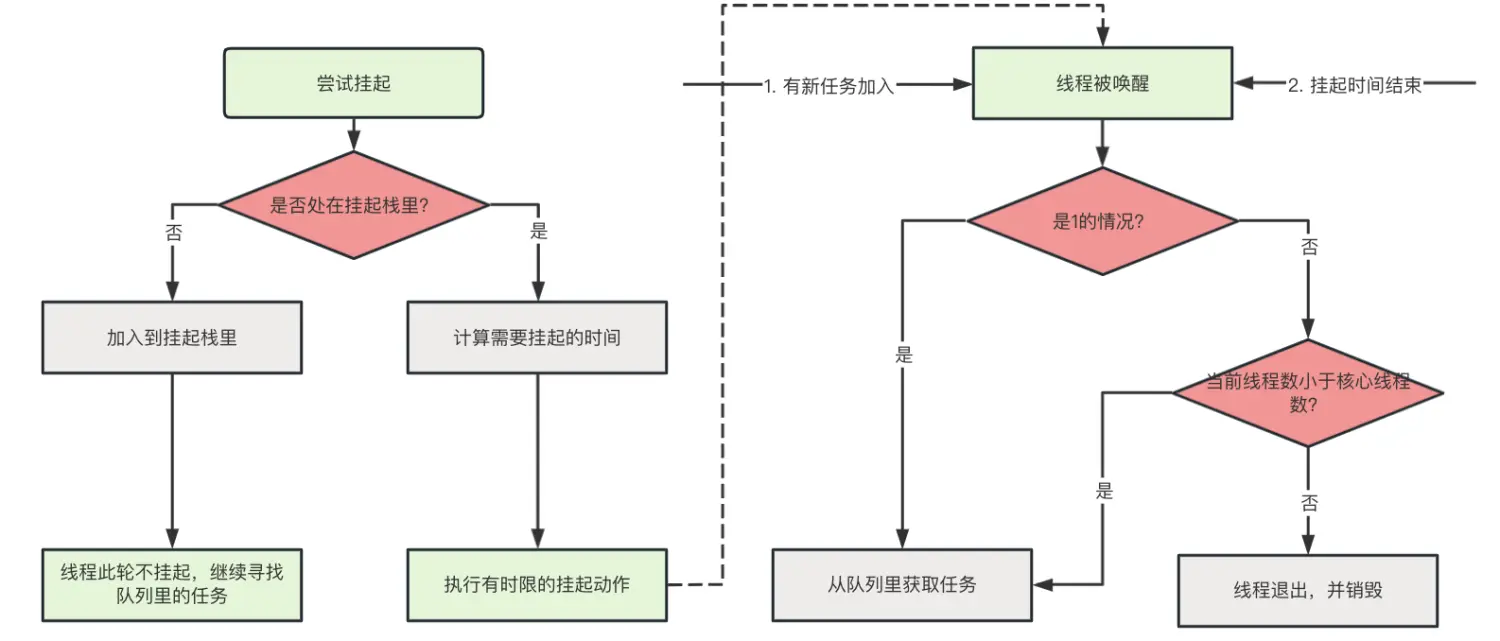
重点在于线程被唤醒后确定是哪种场景下被唤醒的,判断方式也很简单:
==线程挂起时设定了挂起的结束时间点,当线程唤醒后检查当前时间有没有达到结束时间点,若没有,则说明被新加入的任务动作唤醒的==
即使是没有了任务执行,若是当前线程数小于核心线程数,那么也无需销毁线程,继续等待任务的到来即可。
如何更改线程池的默认配置?
先看核心线程数从哪获取的。
1 | internal val CORE_POOL_SIZE = systemProp( |
若是没有设置kotlinx.coroutines.scheduler.core.pool.size属性,那么将取到默认值,比如现在大部分是8核cpu,那么CORE_POOL_SIZE=8。
若要修改,则在线程池启动之前,设置属性值:
1 | System.setProperty("kotlinx.coroutines.scheduler.core.pool.size", "20") |
设置为20,此时我们再按照Demo进行测试,就会发现Dispatchers.Default 任务不会阻塞。
当然,IO任务配置的线程数太多了(默认64),想要降低,则修改属性如下
1 | System.setProperty("kotlinx.coroutines.io.parallelism", "40") |