clip分类检索
本质是将搜索匹配任务转化为分类任务
在视频内容相似性分析中,经常遇到用户输入关键词与视频内容相近度无法有效区分的问题。通过引入负文本标签的概念,结合标签对比算法,提高对视频内容的准确描述和相似性计算,更准确地获取符合需求的视频内容。
原始检索匹配
对每一个视频进行clip视频理解,每一个视频都会输出一个特征向量代表该视频的内容
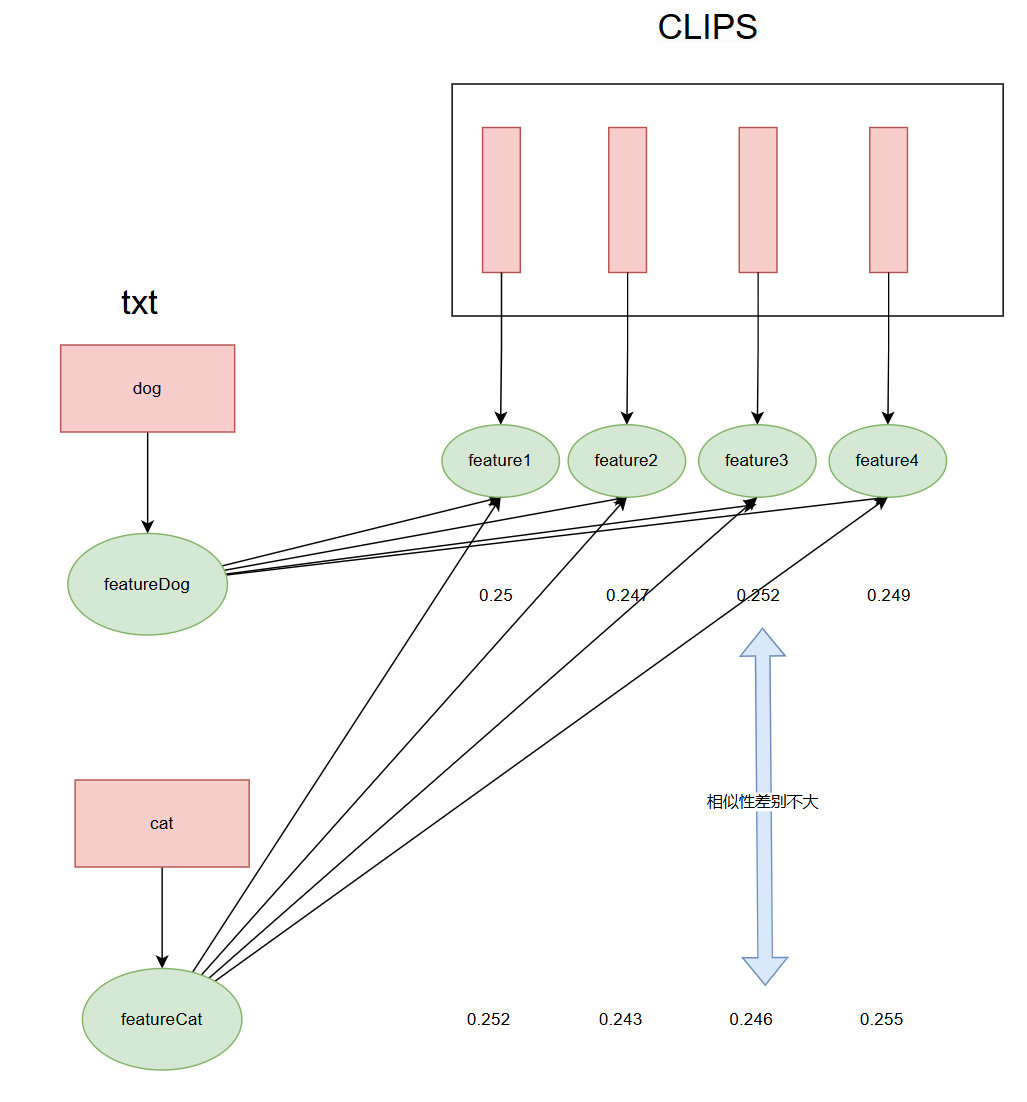
在检索时,当用户输入一个文本(“dog”),将该文本转换为向量,遍历所有的clip并计算相似度,视频内容的相似性分数可能十分接近,难以区分具体描述。在这种情况下不能很好的区分
如果用户输入cat,可能得到相似的结果,相似性分数差别不大
简单来说就是一个视频与dog和cat的相似性分数相近,无法区分到底属于哪一个描述
分类任务
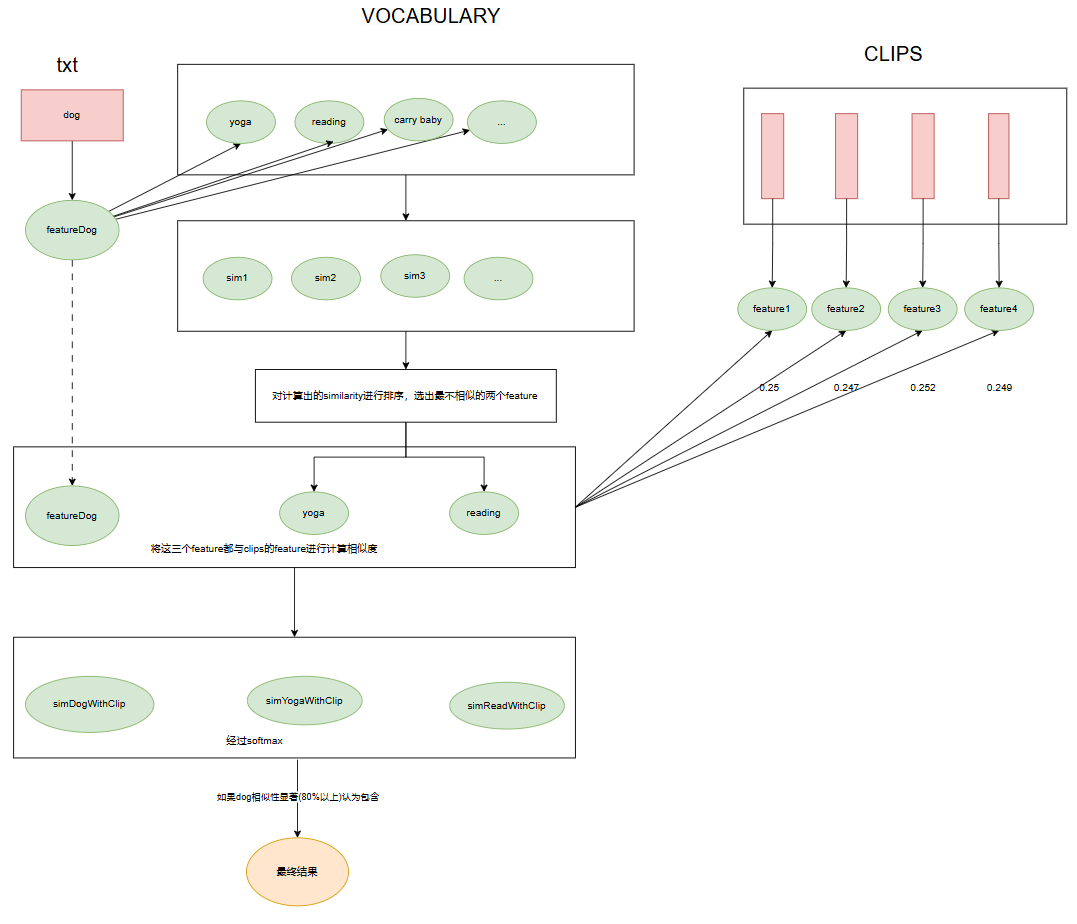
引入预设的9个标签 vocabulary,选择与用户输入最不相近的2个标签作为负文本,结合用户输入标签进行相似性计算。
在APP中预设了9个标签vocabulary
a photo of doing housework with broom or mop
a photo of taking care of baby
a photo of eating or dining
a photo of doing push-up
a photo of running on treadmill
a photo of squatting using barbell
a photo of yoga
a photo of blowing out candles
a photo of reading book
- 在这9个标签中选出与用户输入最不相近的2个标签,称为负文本。再将这3个标签与所有clip的特征向量进行比较,此时由于有负文本的参与,假设dog与9个标签中最不相似的标签是a photo of yoga和a photo of reading book,三个标签的相似性分别为(0.25, 0.248, 0.242),再经过softMax扩大数值,那么如果这个视频真的存在dog,最终dog的相似性将会显著提高(80%以上)
- 标签选择: 根据用户输入的关键词,选择最不相近的2个标签作为负文本。
- 相似性计算: 将用户输入标签、负文本标签与所有视频 clip 的特征向量进行比较。
- 相似性度量: 通过 SoftMax 扩大数值,计算三个标签的相似性分数。
- 结果分析: 若视频内容描述与用户输入标签相似,相似性分数将显著提高,帮助区分视频内容。
- 如果对于同一个视频三者的相似度依然不明显,但其余两个已经是与输入的文本最不相似的一个了,说明并不能很好的认为这个视频描述了用户的输入